Laboratórios ArchCloud
Labs práticos com screenshots e explicações detalhadas — pegando na mão do início ao fim.
🔐
Como configurar MFA no SSH da sua EC2 com Google Authenticator
Médio
30 min
EC2 • SSH • MFA • PAM
Como configurar MFA no SSH da sua EC2 com Google Authenticator
Diagrama Animado
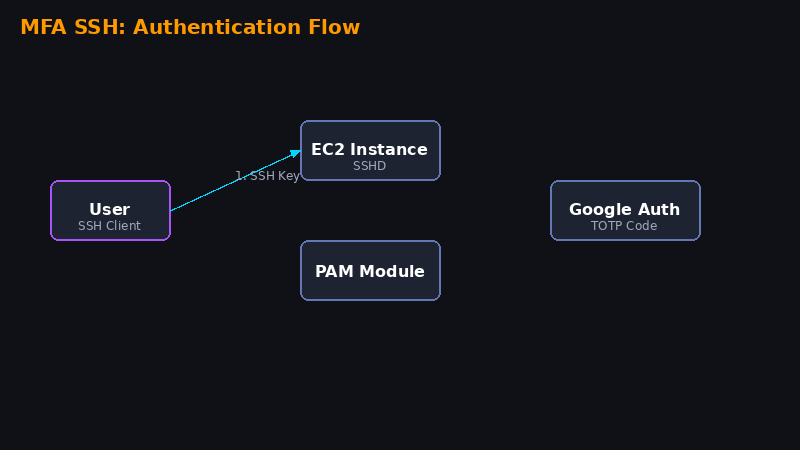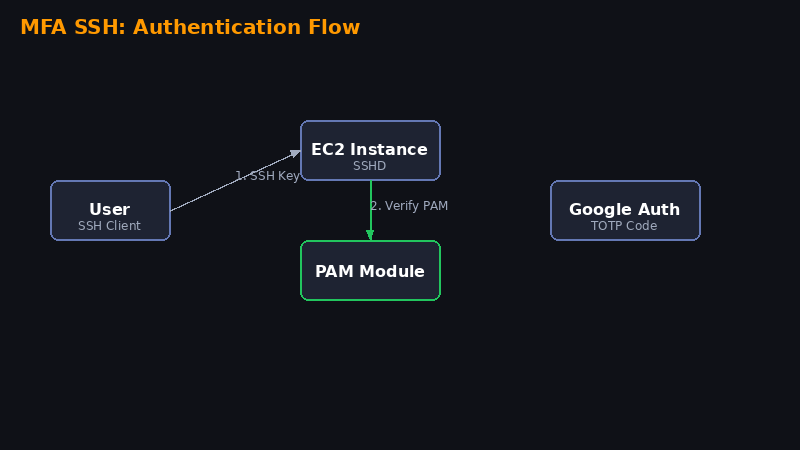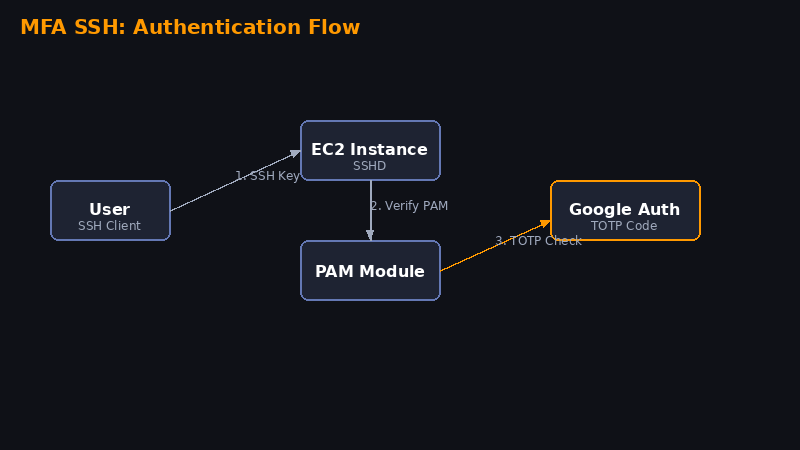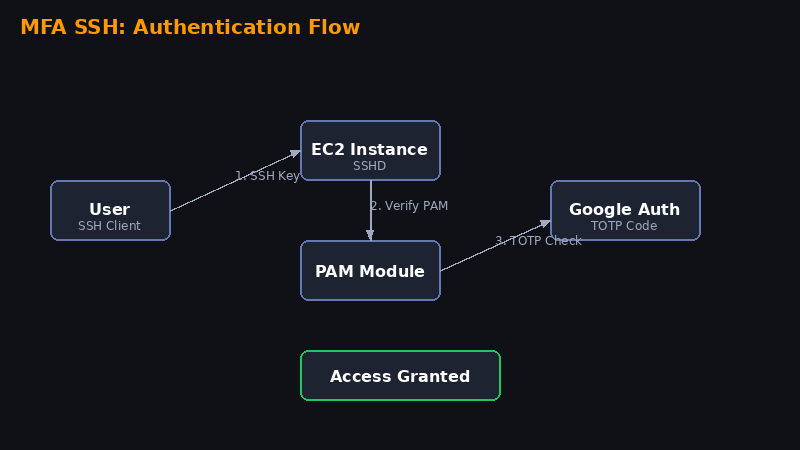
Neste laboratório você vai aprender a adicionar uma camada extra de segurança ao SSH da sua instância EC2, exigindo um código do Google Authenticator além da chave .pem. Isso protege contra acesso não autorizado mesmo se alguém obtiver sua chave privada.

Pré-requisitos
- Uma instância EC2 rodando (Amazon Linux 2023 ou Ubuntu)
- Acesso SSH com chave .pem
- App Google Authenticator instalado no celular
Passo 1 — Criar e acessar a instância EC2
Crie uma instância EC2 no console AWS. Pode ser uma t3.micro (free tier). Selecione Amazon Linux 2023 e crie/selecione um key pair (.pem).
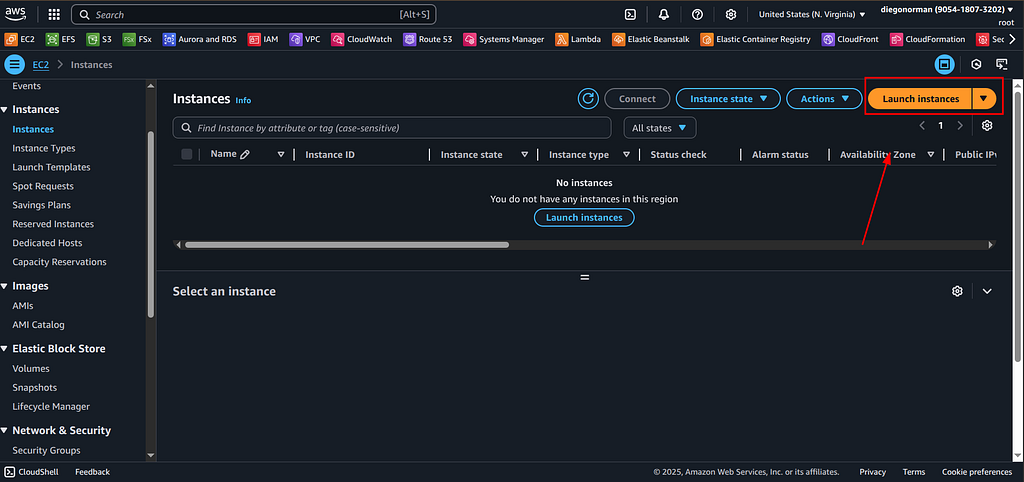
Instância criada! Agora vamos acessá-la. Primeiro, dê permissão à chave:
chmod 400 sua-chave.pemAgora conecte via SSH:
ssh -i sua-chave.pem ec2-user@seu-ip-publico
Passo 2 — Atualizar o sistema e instalar o Google Authenticator
Vamos primeiro atualizar o sistema:
sudo dnf update -y
Agora instale o Google Authenticator e o qrencode (para gerar QR code no terminal):
sudo dnf install google-authenticator qrencode -y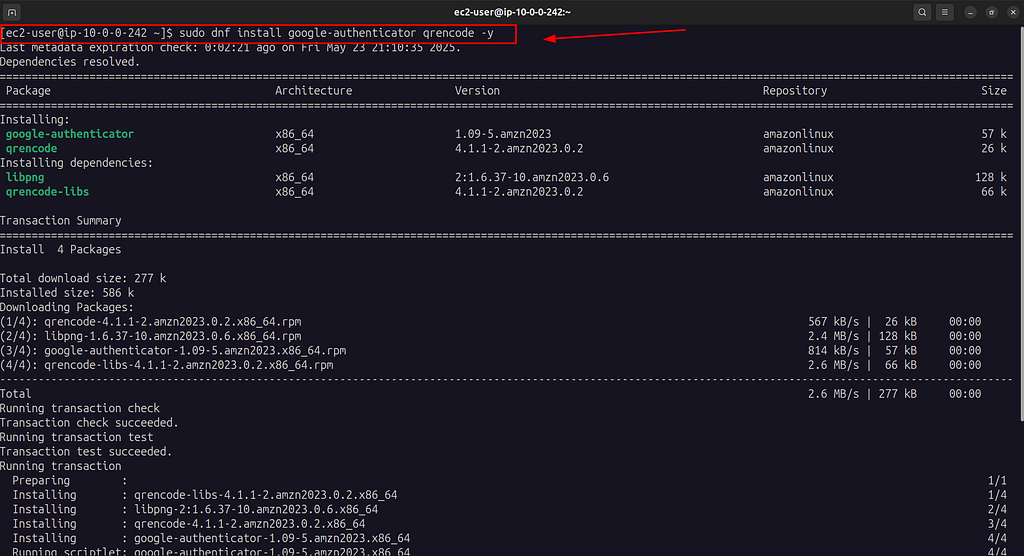
sudo apt update && sudo apt install libpam-google-authenticator -yPasso 3 — Configurar o Google Authenticator
Execute o comando de inicialização. Ele vai gerar um QR code para você escanear com o app:
google-authenticatorO sistema vai fazer várias perguntas. Responda assim:
Do you want authentication tokens to be time-based (y/n) yNesse momento aparece o QR Code. Abra o app Google Authenticator no celular e escaneie:


Continue respondendo as perguntas:
Do you want me to update your "/home/ec2-user/.google_authenticator" file (y/n) y
Do you want to disallow multiple uses of the same authentication token? (y/n) y
By default, a new token is generated every 30 seconds...
Do you want to do so? (y/n) n
Do you want to enable rate-limiting (y/n) yPasso 4 — Configurar o PAM (Pluggable Authentication Module)
Agora precisamos dizer ao sistema para usar o Google Authenticator nas conexões SSH. Edite o arquivo PAM:
sudo vi /etc/pam.d/sshdComente a primeira linha (adicione # no início):
#auth substack password-authE adicione no final do arquivo:
auth required pam_google_authenticator.so
auth required pam_permit.so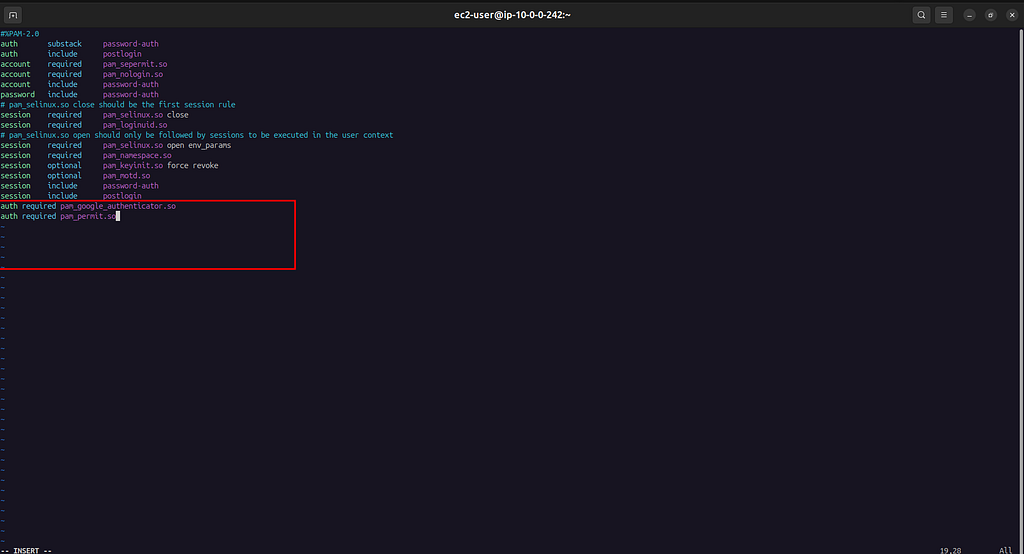
pam_google_authenticator.so nullok em vez de apenas pam_google_authenticator.so.Passo 5 — Configurar o SSHD
Edite a configuração do SSH:
sudo vi /etc/ssh/sshd_config.d/50-redhat.confAltere ChallengeResponseAuthentication no para:
ChallengeResponseAuthentication yesNo final do arquivo, adicione:
AuthenticationMethods publickey,keyboard-interactive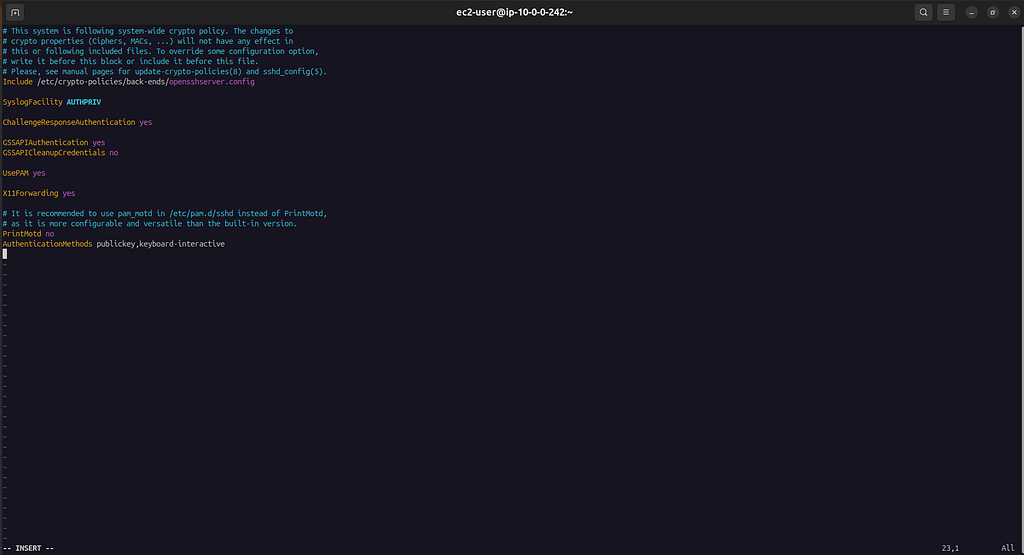
Isso diz ao SSH: "exija a chave .pem E depois peça o código MFA".
Passo 6 — Reiniciar o SSH e testar
sudo systemctl restart sshdNo novo terminal, conecte novamente:
ssh -i sua-chave.pem ec2-user@seu-ip-publicoAgora o sistema vai pedir: Verification code: — digite o código de 6 dígitos do app Google Authenticator!

🎉 Pronto! Sua instância agora exige chave SSH + código MFA para acesso. Segurança de outro nível!
Limpeza
Para evitar cobranças, termine a instância EC2 se não estiver usando: EC2 → Instances → Actions → Terminate.
Conclusão
Você implementou autenticação multifator no SSH, adicionando uma camada essencial de proteção. Mesmo que alguém obtenha sua chave .pem, não conseguirá acessar sem o código do seu celular.
Tags: #AWS #EC2 #SSH #MFA #GoogleAuthenticator #DevSecOps #CloudSecurity
⚡
Upload em Bucket S3 utilizando API Gateway
Médio
35 min
API Gateway • S3 • IAM
Upload em Bucket S3 utilizando API Gateway
Diagrama Animado
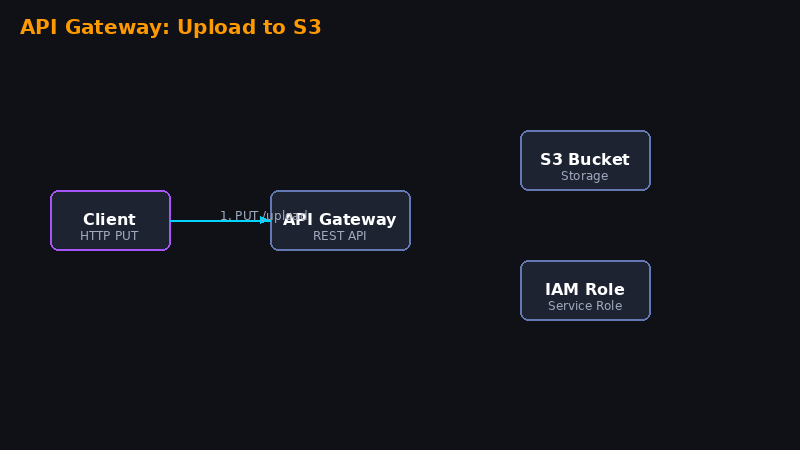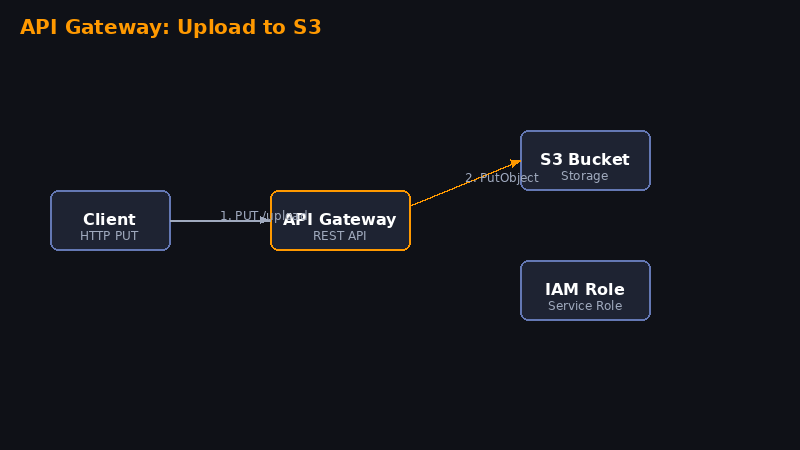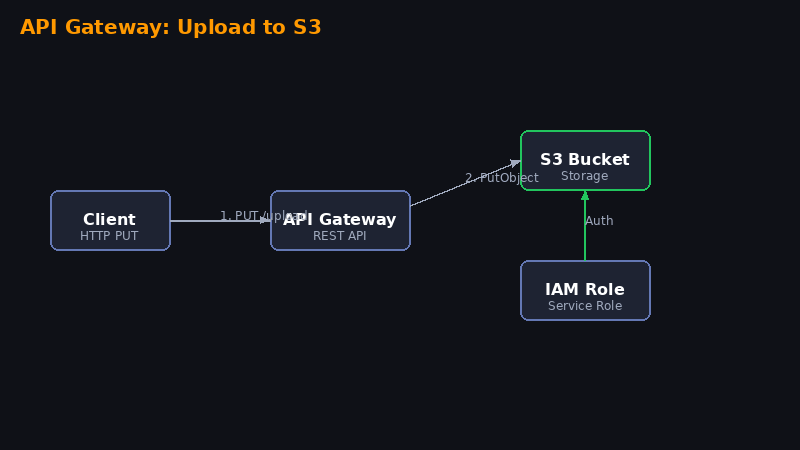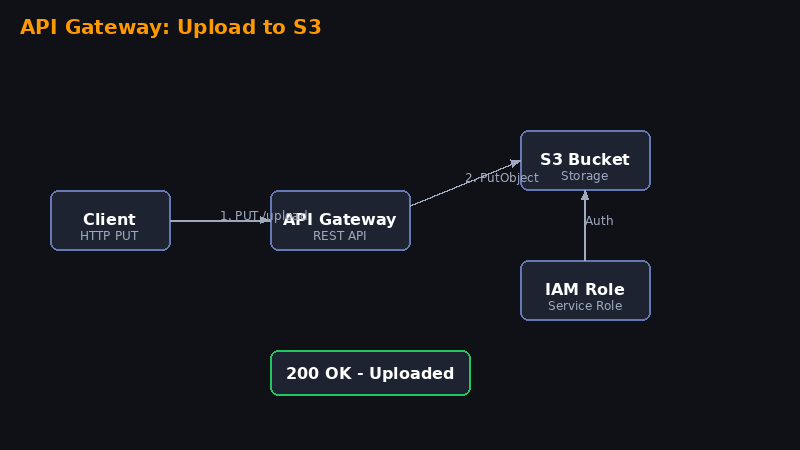
Neste lab você vai criar uma API REST que faz upload direto para o S3 usando integração nativa do API Gateway — sem Lambda, sem servidor. Isso reduz custo e latência.
Passo 1 — Criar um Bucket S3
No AWS Management Console, pressione Alt + S e pesquise por S3.
- Clique em Create Bucket
- Em Bucket Name, insira o nome do seu bucket (ex:
archcloud-upload-lab) - Deixe as configurações padrão e clique em Create Bucket
seu-nome-upload-lab-2025.Passo 2 — Criar uma Role IAM com Permissões
Pressione Alt + S e pesquise por IAM.
- Vá até Roles e clique em Create Role
- Em "Trusted Entity Type", selecione AWS Service
- Em "Use Case", escolha API Gateway e clique em Next
- Busque por
AmazonAPIGatewayPushToCloudWatchLogse selecione - Em "Role Name", coloque:
APIGatewayS3UploadRole - Clique em Create Role
Agora adicione a permissão de S3. Vá na role criada → Add permissions → Create inline policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::archcloud-upload-lab/*"
}
]
}Salve com o nome S3PutObjectPolicy.
Passo 3 — Criar a REST API no API Gateway
Pesquise por API Gateway no console.
- Clique em Create API → REST API → Build
- Nome:
S3UploadAPI - Clique em Create API
Criar o recurso
- Clique em Create Resource
- Resource Name:
{folder}— marque "Configure as proxy resource": NÃO - Dentro de
{folder}, crie outro recurso:{filename}
Sua estrutura deve ficar: /{folder}/{filename}
Criar o método PUT
- Selecione o recurso
{filename} - Clique em Create Method → PUT
- Integration type: AWS Service
- AWS Region:
us-east-1(ou sua região) - AWS Service: Simple Storage Service (S3)
- HTTP method: PUT
- Action Type: Use path override
- Path override:
{bucket}/{key} - Execution role: cole o ARN da role
APIGatewayS3UploadRole
Passo 4 — Configurar o mapeamento de parâmetros
Em Integration Request:
- Em URL Path Parameters, adicione:
bucket→ mapped from:method.request.path.folderkey→ mapped from:method.request.path.filename
Em Method Request → Settings:
- Adicione
Content-Typecomo HTTP Request Header (obrigatório)
Passo 5 — Deploy da API
- Clique em Deploy API
- Stage name:
prod - Clique em Deploy
Copie a Invoke URL que aparece. Ela será algo como:
https://abc123xyz.execute-api.us-east-1.amazonaws.com/prodPasso 6 — Testar o upload!
# Upload de um arquivo de texto
curl -X PUT \
"https://abc123xyz.execute-api.us-east-1.amazonaws.com/prod/archcloud-upload-lab/hello.txt" \
-H "Content-Type: text/plain" \
-d "Hello from API Gateway! Upload direto pro S3 sem Lambda!"
# Upload de uma imagem
curl -X PUT \
"https://abc123xyz.execute-api.us-east-1.amazonaws.com/prod/archcloud-upload-lab/foto.jpg" \
-H "Content-Type: image/jpeg" \
--data-binary @foto.jpgVá no console do S3 e verifique — o arquivo estará lá! 🎉
Limpeza
- Delete a API no API Gateway
- Esvazie e delete o bucket S3
- Delete a Role IAM
Conclusão
Você criou uma API serverless que faz upload direto para o S3 sem nenhuma Lambda. Isso é mais barato, mais rápido e mais simples para casos de upload de arquivos.
🔑
Acessando seu Banco de Dados com Secrets Manager
Fácil
20 min
Secrets Manager • RDS • Python
Acessando seu Banco de Dados com Secrets Manager
Diagrama Animado
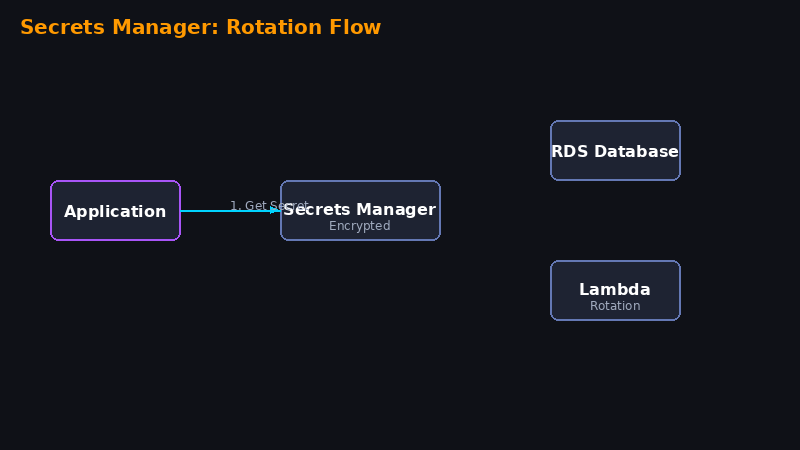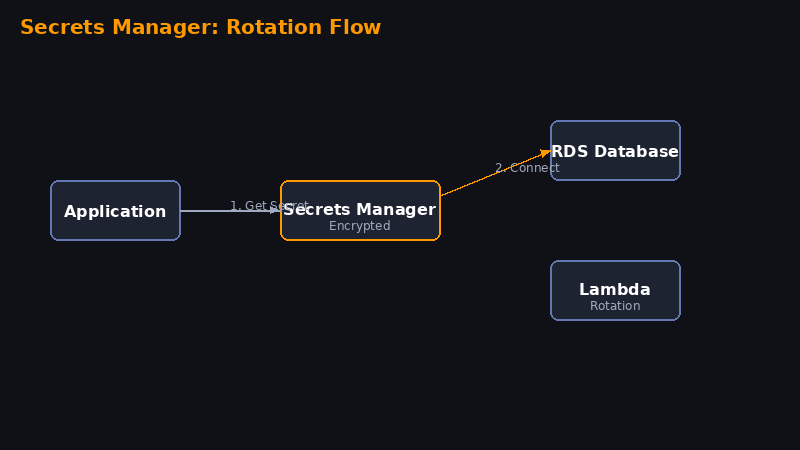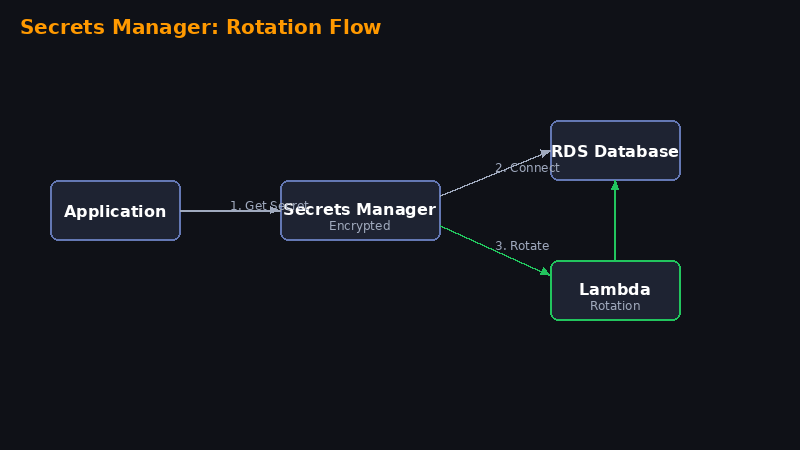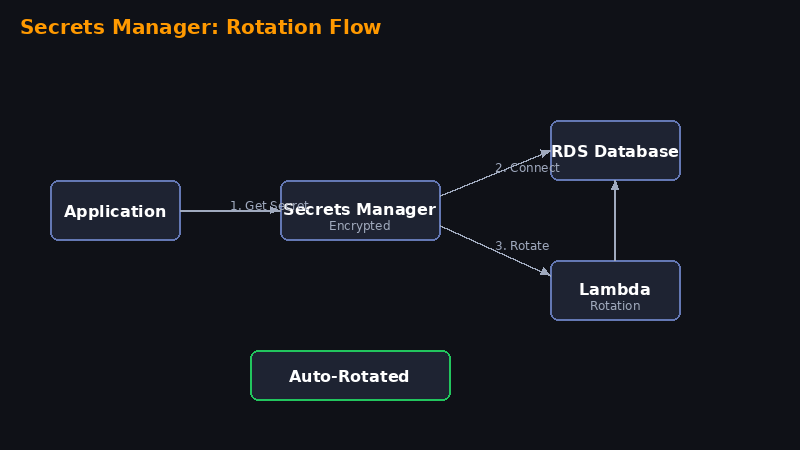
Você sabia que é possível garantir acesso seguro aos seus bancos de dados na nuvem sem expor credenciais sensíveis no código? Com o AWS Secrets Manager você gerencia, recupera e rotaciona automaticamente as credenciais.
Por que usar Secrets Manager?
- Zero hardcoded credentials — nada de senha no código
- Rotação automática — troca a senha do banco a cada X dias
- Auditoria — CloudTrail registra quem acessou cada secret
- Integração nativa — funciona com RDS, Redshift, DocumentDB
Passo 1 — Criar o Secret no Console
Pesquise por Secrets Manager no console AWS.
- Clique em Store a new secret
- Secret type: Credentials for Amazon RDS database (ou "Other type" para secrets genéricos)
- Preencha username e password do seu banco
- Selecione o banco RDS (se tiver um)
- Secret name:
prod/myapp/database - Clique em Store
Ou via CLI:
aws secretsmanager create-secret \
--name prod/myapp/database \
--description "Credenciais do banco de produção" \
--secret-string '{
"username": "admin",
"password": "MinhaSenhaSegura123!",
"host": "mydb.cluster-xxxxx.us-east-1.rds.amazonaws.com",
"port": "5432",
"dbname": "myapp"
}'Passo 2 — Acessar o Secret via código Python
Instale o boto3 se ainda não tiver:
pip install boto3Agora crie o arquivo db_connection.py:
import boto3
import json
def get_db_credentials():
"""Busca as credenciais do banco no Secrets Manager"""
client = boto3.client('secretsmanager', region_name='us-east-1')
response = client.get_secret_value(
SecretId='prod/myapp/database'
)
# O secret vem como string JSON, precisamos fazer parse
secret = json.loads(response['SecretString'])
return secret
# Uso:
creds = get_db_credentials()
print(f"Conectando em: {creds['host']}:{creds['port']}")
print(f"Database: {creds['dbname']}")
print(f"User: {creds['username']}")
# NUNCA faça print da senha em produção!Passo 3 — Conectar no banco usando o secret
Exemplo completo com psycopg2 (PostgreSQL):
import boto3, json, psycopg2
def get_connection():
client = boto3.client('secretsmanager', region_name='us-east-1')
secret = json.loads(
client.get_secret_value(SecretId='prod/myapp/database')['SecretString']
)
conn = psycopg2.connect(
host=secret['host'],
port=secret['port'],
dbname=secret['dbname'],
user=secret['username'],
password=secret['password']
)
return conn
# Uso
conn = get_connection()
cursor = conn.cursor()
cursor.execute("SELECT NOW()")
print(cursor.fetchone())Passo 4 — Habilitar rotação automática
No console do Secrets Manager:
- Selecione seu secret
- Clique em Edit rotation
- Marque Enable automatic rotation
- Rotation interval: 30 days
- A AWS cria uma Lambda automaticamente que rotaciona a senha
Passo 5 — IAM Policy para sua aplicação
Sua EC2/Lambda/ECS precisa desta permissão:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": "secretsmanager:GetSecretValue",
"Resource": "arn:aws:secretsmanager:us-east-1:*:secret:prod/myapp/*"
}]
}Conclusão
Agora suas credenciais estão seguras, rotacionam automaticamente, e sua aplicação nunca mais terá senhas hardcoded. Isso é o mínimo para qualquer aplicação em produção na AWS.
📦
Aplicação Node.js para Upload de Arquivos no S3
Fácil
25 min
Node.js • S3 • SDK v3 • Express
Aplicação Node.js para Upload de Arquivos no S3
Diagrama Animado
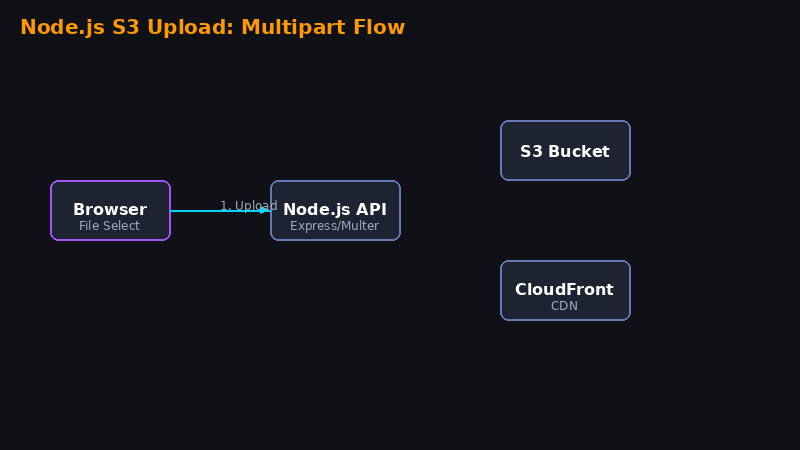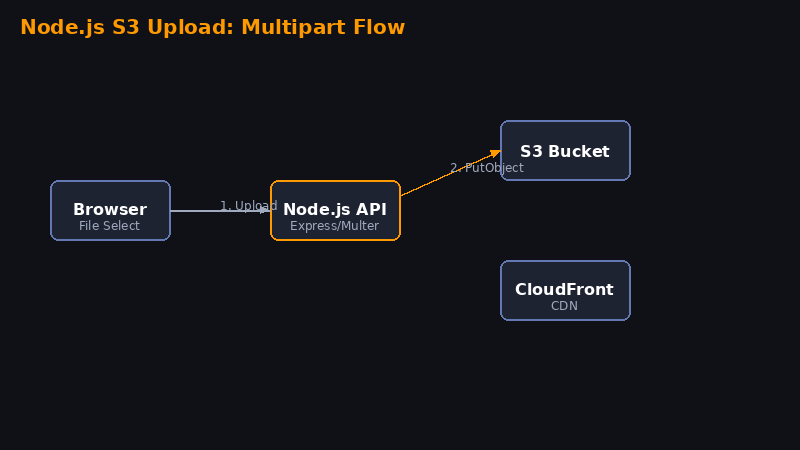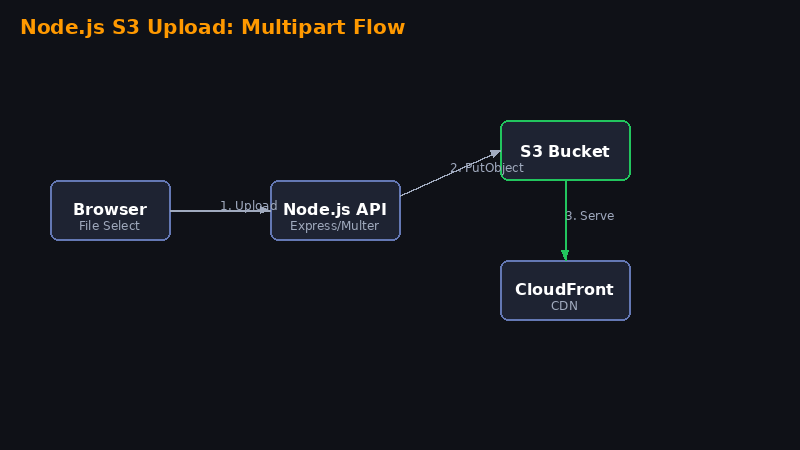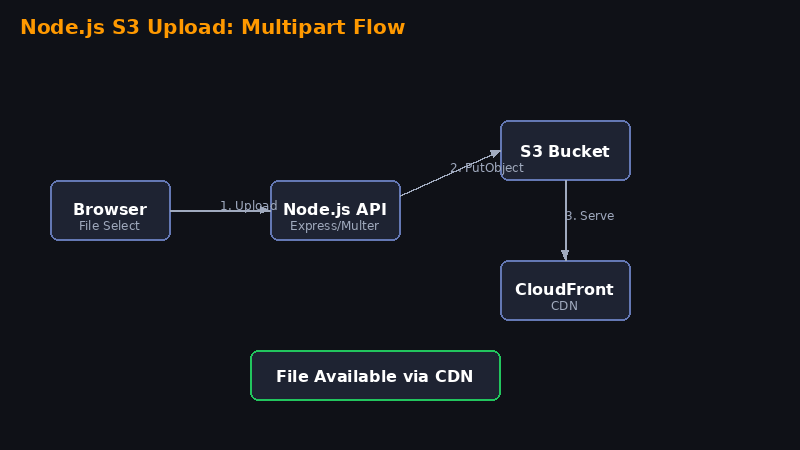
Vamos criar uma aplicação web completa com Node.js que permite upload de arquivos via formulário HTML direto para um bucket S3 usando o AWS SDK v3.
Passo 1 — Configuração do Projeto
Crie uma nova pasta e inicialize o projeto:
mkdir node-s3-upload
cd node-s3-upload
npm init -yInstale as dependências necessárias:
npm install express cors multer @aws-sdk/client-s3 @aws-sdk/lib-storage dotenvInstale o nodemon para desenvolvimento:
npm install --save-dev nodemonPasso 2 — Criar o arquivo .env
Crie um arquivo .env na raiz do projeto:
AWS_REGION=us-east-1
AWS_ACCESS_KEY_ID=sua-access-key-aqui
AWS_SECRET_ACCESS_KEY=sua-secret-key-aqui
S3_BUCKET_NAME=meu-bucket-upload-2025
PORT=3000.env no seu .gitignore.Passo 3 — Criar o servidor (server.js)
require('dotenv').config();
const express = require('express');
const multer = require('multer');
const { S3Client, PutObjectCommand } = require('@aws-sdk/client-s3');
const path = require('path');
const app = express();
const upload = multer({ storage: multer.memoryStorage() });
// Configurar cliente S3
const s3Client = new S3Client({
region: process.env.AWS_REGION,
credentials: {
accessKeyId: process.env.AWS_ACCESS_KEY_ID,
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY
}
});
// Servir página HTML
app.get('/', (req, res) => {
res.sendFile(path.join(__dirname, 'index.html'));
});
// Rota de upload
app.post('/upload', upload.single('file'), async (req, res) => {
try {
if (!req.file) {
return res.status(400).json({ error: 'Nenhum arquivo enviado' });
}
const fileName = `uploads/${Date.now()}-${req.file.originalname}`;
const command = new PutObjectCommand({
Bucket: process.env.S3_BUCKET_NAME,
Key: fileName,
Body: req.file.buffer,
ContentType: req.file.mimetype
});
await s3Client.send(command);
res.json({
message: '✅ Upload realizado com sucesso!',
fileName: fileName,
url: `https://${process.env.S3_BUCKET_NAME}.s3.amazonaws.com/${fileName}`
});
} catch (error) {
console.error('Erro no upload:', error);
res.status(500).json({ error: 'Erro ao fazer upload' });
}
});
app.listen(process.env.PORT, () => {
console.log(`🚀 Servidor rodando em http://localhost:${process.env.PORT}`);
});Passo 4 — Criar a página HTML (index.html)
<!DOCTYPE html>
<html>
<head>
<title>Upload para S3</title>
</head>
<body>
<h1>Upload de Arquivo para S3</h1>
<form id="uploadForm" enctype="multipart/form-data">
<input type="file" name="file" id="file" required>
<button type="submit">Enviar para S3</button>
</form>
<div id="result"></div>
<script>
document.getElementById('uploadForm').addEventListener('submit', async (e) => {
e.preventDefault();
const formData = new FormData();
formData.append('file', document.getElementById('file').files[0]);
const res = await fetch('/upload', { method: 'POST', body: formData });
const data = await res.json();
document.getElementById('result').innerHTML = '<pre>' + JSON.stringify(data, null, 2) + '</pre>';
});
</script>
</body>
</html>Passo 5 — Criar o Bucket S3
# Criar bucket
aws s3 mb s3://meu-bucket-upload-2025 --region us-east-1
# Configurar CORS (necessário para upload via browser)
aws s3api put-bucket-cors --bucket meu-bucket-upload-2025 \
--cors-configuration '{
"CORSRules": [{
"AllowedOrigins": ["*"],
"AllowedMethods": ["PUT", "POST", "GET"],
"AllowedHeaders": ["*"]
}]
}'Passo 6 — Rodar e testar!
node server.jsAbra http://localhost:3000, selecione um arquivo e clique em enviar. Verifique no console do S3 que o arquivo apareceu na pasta uploads/!
Conclusão
Você criou uma aplicação completa de upload para S3 com Node.js. Essa é a base para qualquer sistema que precisa armazenar arquivos na nuvem — fotos de perfil, documentos, backups, etc.
🔄
Conexão Segura AWS Transfer Family SFTP com S3
Médio
40 min
Transfer Family • S3 • IAM • SFTP
Conexão Segura AWS Transfer Family SFTP com S3
Diagrama Animado
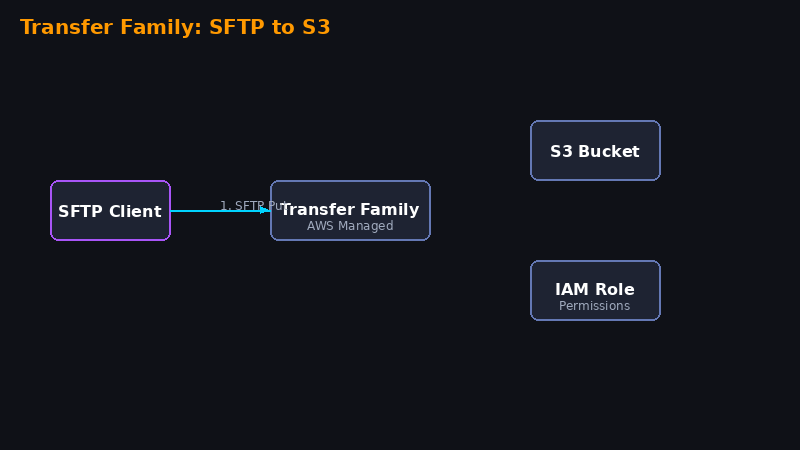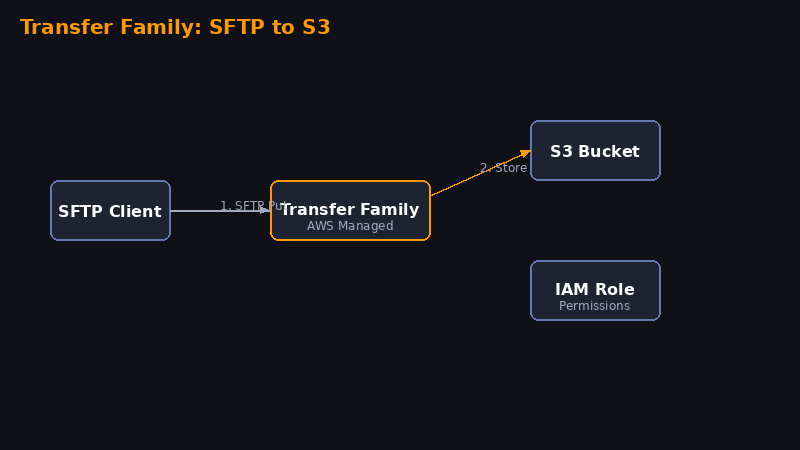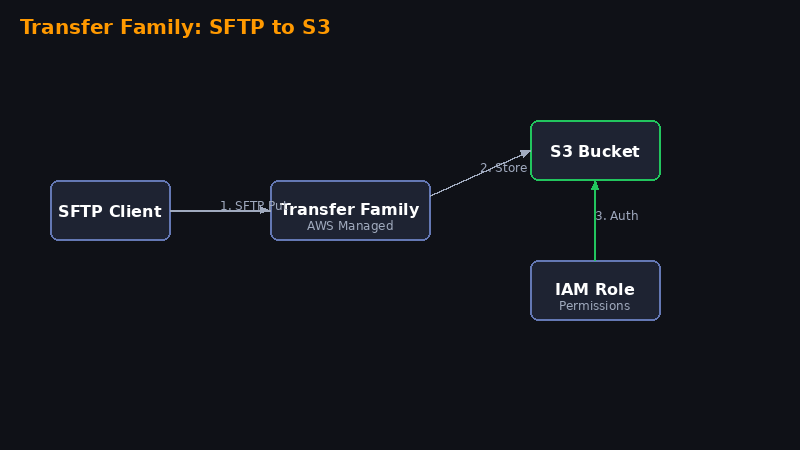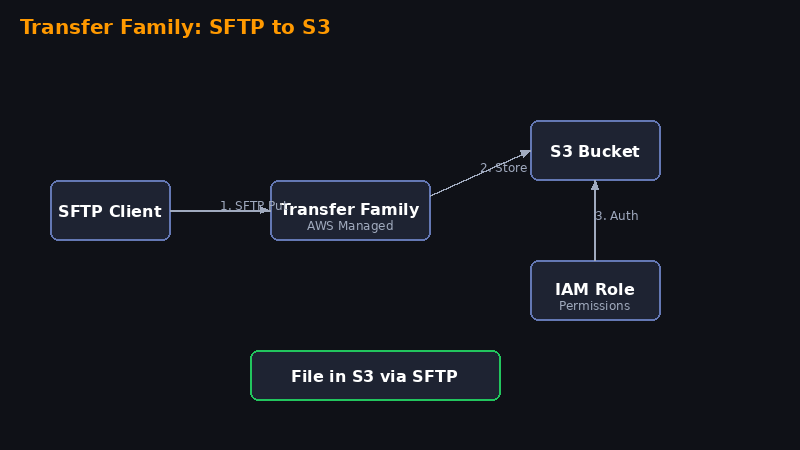
Neste lab você vai criar uma conexão SFTP segura usando AWS Transfer Family para enviar dados sensíveis diretamente para um bucket S3 privado. Ideal para integrações com parceiros que usam SFTP.

Passo 1 — Criar um Bucket S3 Privado
Crie um bucket com todas as configurações de bloqueio público ativadas:
aws s3 mb s3://sftp-dados-sensiveis-2025 --region us-east-1
# Bloquear todo acesso público
aws s3api put-public-access-block \
--bucket sftp-dados-sensiveis-2025 \
--public-access-block-configuration \
BlockPublicAcls=true,IgnorePublicAcls=true,BlockPublicPolicy=true,RestrictPublicBuckets=truePasso 2 — Criar a Policy IAM
Vá em IAM → Policies → Create policy. Use o JSON:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowListBucket",
"Effect": "Allow",
"Action": ["s3:ListBucket", "s3:GetBucketLocation"],
"Resource": "arn:aws:s3:::sftp-dados-sensiveis-2025"
},
{
"Sid": "AllowObjectOperations",
"Effect": "Allow",
"Action": ["s3:PutObject", "s3:GetObject", "s3:DeleteObject", "s3:GetObjectVersion"],
"Resource": "arn:aws:s3:::sftp-dados-sensiveis-2025/*"
}
]
}Nome da policy: TransferFamilyS3Access
Passo 3 — Criar a Role IAM para Transfer Family
IAM → Roles → Create role:
- Trusted entity: AWS Service
- Use case: Transfer
- Attach a policy
TransferFamilyS3Access - Role name:
TransferFamilySFTPRole
Passo 4 — Criar o servidor SFTP
Pesquise por AWS Transfer Family no console:
- Clique em Create server
- Protocol: SFTP
- Identity provider: Service managed
- Endpoint type: Publicly accessible
- Logging: selecione um CloudWatch log group (ou crie um novo)
- Clique em Create server
Aguarde o status ficar Online (pode levar 2-3 minutos).
Passo 5 — Criar usuário SFTP
No servidor criado, clique em Add user:
- Username:
parceiro-dados - Role: selecione
TransferFamilySFTPRole - Home directory:
/sftp-dados-sensiveis-2025 - Restricted: marque para restringir ao home directory
- SSH public key: cole sua chave pública (
cat ~/.ssh/id_rsa.pub)
ssh-keygen -t rsa -b 4096 -f sftp-keyPasso 6 — Testar a conexão SFTP
O endpoint do servidor aparece no console (algo como s-xxxxxxxxx.server.transfer.us-east-1.amazonaws.com):
# Conectar via SFTP
sftp -i sftp-key parceiro-dados@s-xxxxxxxxx.server.transfer.us-east-1.amazonaws.com
# Dentro do SFTP:
sftp> pwd
sftp> put arquivo-sensivel.csv
sftp> ls
sftp> exitVerifique no S3 — o arquivo estará no bucket! 🎉
Limpeza
- Delete o servidor Transfer Family (⚠️ cobra por hora enquanto ativo!)
- Esvazie e delete o bucket S3
- Delete a Role e Policy IAM
Conclusão
Você criou um servidor SFTP gerenciado pela AWS que armazena dados diretamente no S3. Perfeito para receber arquivos de parceiros, integrações legadas, ou qualquer sistema que use SFTP.
⚡
API CRUD Serverless: Lambda + DynamoDB + API Gateway
Médio
45 min
Lambda • DynamoDB • API Gateway
API CRUD Serverless: Lambda + DynamoDB + API Gateway
Diagrama Animado

Vamos criar uma API CRUD completa 100% serverless. Zero servidores para gerenciar, paga só pelo que usar, escala automaticamente.
Passo 1 — Criar tabela DynamoDB
Pesquise por DynamoDB no console:
- Clique em Create table
- Table name:
Products - Partition key:
id(String) - Table settings: Default settings (On-demand capacity)
- Clique em Create table
Ou via CLI:
aws dynamodb create-table \
--table-name Products \
--attribute-definitions AttributeName=id,AttributeType=S \
--key-schema AttributeName=id,KeyType=HASH \
--billing-mode PAY_PER_REQUESTPasso 2 — Criar a Lambda Function
Pesquise por Lambda → Create function:
- Function name:
products-api - Runtime: Python 3.12
- Architecture: arm64 (mais barato)
- Execution role: Create a new role with basic Lambda permissions
Após criar, vá na role da Lambda (Configuration → Permissions → Role name) e adicione a policy:
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": ["dynamodb:PutItem", "dynamodb:GetItem", "dynamodb:Scan", "dynamodb:DeleteItem", "dynamodb:UpdateItem"],
"Resource": "arn:aws:dynamodb:us-east-1:*:table/Products"
}]
}Passo 3 — Código da Lambda
Cole este código no editor da Lambda:
import json
import boto3
import uuid
from decimal import Decimal
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Products')
class DecimalEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, Decimal):
return float(obj)
return super().default(obj)
def lambda_handler(event, context):
method = event['requestContext']['http']['method']
try:
if method == 'GET':
# Listar todos os produtos
result = table.scan()
return {
'statusCode': 200,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps(result['Items'], cls=DecimalEncoder)
}
elif method == 'POST':
# Criar produto
body = json.loads(event['body'])
item = {
'id': str(uuid.uuid4()),
'name': body['name'],
'price': Decimal(str(body['price'])),
'description': body.get('description', '')
}
table.put_item(Item=item)
return {
'statusCode': 201,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps(item, cls=DecimalEncoder)
}
elif method == 'DELETE':
# Deletar produto
product_id = event['pathParameters']['id']
table.delete_item(Key={'id': product_id})
return {'statusCode': 204}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}Clique em Deploy para salvar.
Passo 4 — Criar HTTP API no API Gateway
Pesquise por API Gateway:
- Clique em Create API → HTTP API → Build
- Add integration: Lambda → selecione
products-api - API name:
products-api - Clique em Next
Configure as rotas:
GET /products→ products-apiPOST /products→ products-apiDELETE /products/{id}→ products-api
Stage: $default (auto-deploy). Clique em Create.
Passo 5 — Testar a API!
Copie a Invoke URL do API Gateway e teste:
# Criar um produto
curl -X POST https://xxxxx.execute-api.us-east-1.amazonaws.com/products \
-H "Content-Type: application/json" \
-d '{"name": "Curso AWS", "price": 49.90, "description": "Curso completo de AWS"}'
# Listar produtos
curl https://xxxxx.execute-api.us-east-1.amazonaws.com/products
# Deletar produto (use o id retornado no POST)
curl -X DELETE https://xxxxx.execute-api.us-east-1.amazonaws.com/products/uuid-aquiConclusão
Você criou uma API CRUD completa sem gerenciar nenhum servidor. Essa é a base para qualquer microserviço serverless na AWS — adicione autenticação com Cognito e você tem um backend de produção.
⚙️
Automação EC2 com N8N: Start/Stop por Horário Comercial
Médio
40 min
EC2 • N8N • Python • FinOps • GitHub Actions
Automação EC2 com N8N: Start/Stop por Horário Comercial
Automatize o start/stop de EC2 por horario comercial com N8N + GitHub Actions + OIDC. Economia de ~65% em instancias que so rodam em horario comercial.
Fluxo
- Setup (1x): Cria EC2 com UserData que instala Docker/Apache automaticamente no boot
- 08:00 diario: N8N → GitHub Actions →
start_ec2.py(liga EC2, UserData configura tudo) - 18:00 diario: N8N → GitHub Actions →
stop_ec2.py(desliga EC2)
Passo 1 — Estrutura do Repositorio
github.com/diegonorman/automation-ec2-deployment
automation-ec2-deployment/
├── .github/workflows/
│ ├── start-ec2.yml # Liga instancias (workflow_dispatch)
│ ├── stop-ec2.yml # Desliga instancias (workflow_dispatch)
│ └── setup-ec2.yml # Cria EC2 nova (one-time)
├── start_ec2.py # Filtra por tags e inicia
├── stop_ec2.py # Filtra por tags e para
├── setup_ec2.py # Cria EC2 com UserData
└── requirements.txt # boto3Passo 2 — Setup: Criar EC2 (setup_ec2.py) — Roda 1x
Cria instancia com UserData que configura tudo no boot (Docker, Apache):
import boto3, os, argparse
REGION = 'us-east-1'
USER_DATA = '''#!/bin/bash
sudo apt update -y
sudo apt install -y apache2 docker.io
sudo systemctl start apache2
sudo systemctl enable apache2
sudo systemctl start docker
sudo systemctl enable docker
echo "<h1>Instancia configurada!</h1>" > /var/www/html/index.html
'''
ec2 = boto3.client('ec2', region_name=REGION)
# Buscar AMI Ubuntu 22.04 ARM64
response = ec2.describe_images(Filters=[
{'Name': 'name', 'Values': ['ubuntu-minimal/images/hvm-ssd/ubuntu-jammy-22.04-arm64-minimal-*']},
{'Name': 'architecture', 'Values': ['arm64']},
{'Name': 'owner-alias', 'Values': ['amazon']}
])
AMI_ID = response['Images'][0]['ImageId']
ec2.run_instances(
ImageId=AMI_ID,
InstanceType='t4g.micro',
MinCount=1, MaxCount=1,
UserData=USER_DATA,
IamInstanceProfile={'Arn': 'arn:aws:iam::ACCOUNT:instance-profile/ROLE-SSM'},
TagSpecifications=[{
'ResourceType': 'instance',
'Tags': [
{'Key': 'Name', 'Value': 'Git-deployment-CI/CD'},
{'Key': 'Environment', 'Value': 'production'},
{'Key': 'Owner', 'Value': 'Norman'},
{'Key': 'Team', 'Value': 'DevOps'}
]
}],
BlockDeviceMappings=[{
'DeviceName': '/dev/xvda',
'Ebs': {'VolumeSize': 8, 'VolumeType': 'gp3', 'DeleteOnTermination': True}
}]
)Passo 3 — Start (start_ec2.py) — Roda diario 08:00
Filtra por tags e liga instancias paradas:
import boto3, os
REGION = 'us-east-1'
TAG_FILTERS = [
{'Name': 'tag:Environment', 'Values': ['production']},
{'Name': 'tag:Owner', 'Values': ['Norman']},
{'Name': 'tag:Team', 'Values': ['DevOps']}
]
ec2 = boto3.client('ec2', region_name=REGION,
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),
aws_session_token=os.getenv('AWS_SESSION_TOKEN'))
instances = ec2.describe_instances(Filters=TAG_FILTERS)
ids = [i['InstanceId'] for r in instances['Reservations']
for i in r['Instances'] if i['State']['Name'] in ['stopped','stopping']]
if ids:
ec2.start_instances(InstanceIds=ids)
print(f"Iniciadas: {ids}")
else:
print("Nenhuma instancia parada")Passo 4 — Stop (stop_ec2.py) — Roda diario 18:00
import boto3, os
REGION = 'us-east-1'
TAG_FILTERS = [
{'Name': 'tag:Environment', 'Values': ['production']},
{'Name': 'tag:Owner', 'Values': ['Norman']},
{'Name': 'tag:Team', 'Values': ['DevOps']}
]
ec2 = boto3.client('ec2', region_name=REGION,
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),
aws_session_token=os.getenv('AWS_SESSION_TOKEN'))
instances = ec2.describe_instances(Filters=TAG_FILTERS)
ids = [i['InstanceId'] for r in instances['Reservations']
for i in r['Instances'] if i['State']['Name'] == 'running']
if ids:
ec2.stop_instances(InstanceIds=ids)
print(f"Paradas: {ids}")
else:
print("Nenhuma rodando")Passo 5 — Configurar OIDC (GitHub + AWS)
OIDC permite que o GitHub Actions assuma uma IAM Role sem access keys. Mais seguro e sem rotacao de credenciais.
5.1 — Criar Identity Provider no IAM
# Criar OIDC Provider para GitHub
aws iam create-open-id-connect-provider \
--url https://token.actions.githubusercontent.com \
--client-id-list sts.amazonaws.com \
--thumbprint-list 6938fd4d98bab03faadb97b34396831e3780aea15.2 — Criar IAM Role para GitHub Actions
# Trust policy - permite apenas SEU repo assumir a role
cat > trust-policy.json << 'EOF'
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {
"Federated": "arn:aws:iam::ACCOUNT_ID:oidc-provider/token.actions.githubusercontent.com"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"token.actions.githubusercontent.com:aud": "sts.amazonaws.com"
},
"StringLike": {
"token.actions.githubusercontent.com:sub": "repo:diegonorman/automation-ec2-deployment:*"
}
}
}]
}
EOF
aws iam create-role \
--role-name GitAction-EC2-Pipeline \
--assume-role-policy-document file://trust-policy.json5.3 — Anexar permissoes na Role
# Policy com least privilege para EC2 start/stop
cat > ec2-policy.json << 'EOF'
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:StartInstances",
"ec2:StopInstances",
"ec2:DescribeInstances",
"ec2:DescribeImages",
"ec2:RunInstances",
"ec2:CreateTags"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::ACCOUNT_ID:role/ROLE-SSM"
}
]
}
EOF
aws iam put-role-policy \
--role-name GitAction-EC2-Pipeline \
--policy-name EC2StartStop \
--policy-document file://ec2-policy.jsonValidacao:
aws iam get-role --role-name GitAction-EC2-Pipeline \
--query 'Role.Arn' --output text
# arn:aws:iam::ACCOUNT_ID:role/GitAction-EC2-Pipeline5.4 — Usar no GitHub Actions Workflow
No workflow, adicione permissions e use role-to-assume:
name: Start EC2
on: workflow_dispatch
permissions:
id-token: write # OBRIGATORIO para OIDC
contents: read
jobs:
start-ec2:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with: { python-version: '3.11' }
- run: pip install -r requirements.txt
- name: Configure AWS (OIDC - sem access keys!)
uses: aws-actions/configure-aws-credentials@v3
with:
role-to-assume: arn:aws:iam::ACCOUNT_ID:role/GitAction-EC2-Pipeline
aws-region: us-east-1
- name: Start EC2
run: python start_ec2.pyAWS_ACCESS_KEY_ID nos secrets do repo. O OIDC gera credenciais temporarias automaticamente a cada execucao.Passo 6 — Configurar N8N
No N8N, crie workflows que disparam os GitHub Actions via API:
- 08:00 seg-sex: Schedule Trigger → HTTP Request POST
/repos/diegonorman/automation-ec2-deployment/actions/workflows/start-ec2.yml/dispatches - 18:00 seg-sex: Schedule Trigger → HTTP Request POST
/repos/.../workflows/stop-ec2.yml/dispatches
Header: Authorization: Bearer ghp_SEU_TOKEN | Body: {"ref":"main"}
Workflow N8N (Copiar e Importar)
{
"name": "EC2 Start/Setup/Stop Automation",
"nodes": [
{
"parameters": {
"rule": {"interval": [{"field": "cronExpression", "expression": "0 8 * * 1-5"}]}
},
"id": "cron-start",
"name": "Cron 8h (Seg-Sex)",
"type": "n8n-nodes-base.scheduleTrigger",
"typeVersion": 1.2,
"position": [240, 300]
},
{
"parameters": {
"rule": {"interval": [{"field": "cronExpression", "expression": "0 18 * * 1-5"}]}
},
"id": "cron-stop",
"name": "Cron 18h (Seg-Sex)",
"type": "n8n-nodes-base.scheduleTrigger",
"typeVersion": 1.2,
"position": [240, 520]
},
{
"parameters": {
"authentication": "oAuth2",
"resource": "workflow",
"owner": {"__rl": true, "mode": "list", "value": "diegonorman"},
"repository": {"__rl": true, "mode": "list", "value": "automation-ec2-deployment"},
"workflowId": {"__rl": true, "mode": "list", "value": "start-ec2.yml"}
},
"id": "start",
"name": "Dispatch Start",
"type": "n8n-nodes-base.github",
"typeVersion": 1.1,
"position": [480, 300],
"credentials": {"githubOAuth2Api": {"id": "", "name": "GitHub account"}}
},
{
"parameters": {
"authentication": "oAuth2",
"resource": "workflow",
"owner": {"__rl": true, "mode": "list", "value": "diegonorman"},
"repository": {"__rl": true, "mode": "list", "value": "automation-ec2-deployment"},
"workflowId": {"__rl": true, "mode": "list", "value": "setup-ec2.yml"}
},
"id": "setup",
"name": "Dispatch Setup",
"type": "n8n-nodes-base.github",
"typeVersion": 1.1,
"position": [700, 300],
"credentials": {"githubOAuth2Api": {"id": "", "name": "GitHub account"}}
},
{
"parameters": {
"authentication": "oAuth2",
"resource": "workflow",
"owner": {"__rl": true, "mode": "list", "value": "diegonorman"},
"repository": {"__rl": true, "mode": "list", "value": "automation-ec2-deployment"},
"workflowId": {"__rl": true, "mode": "list", "value": "stop-ec2.yml"}
},
"id": "stop",
"name": "Dispatch Stop",
"type": "n8n-nodes-base.github",
"typeVersion": 1.1,
"position": [480, 520],
"credentials": {"githubOAuth2Api": {"id": "", "name": "GitHub account"}}
},
{
"parameters": {
"channel": "#infra",
"text": "=EC2 {{ $node.name }}: executado com sucesso - {{ new Date().toLocaleString('pt-BR') }}"
},
"id": "slack",
"name": "Notificar Slack",
"type": "n8n-nodes-base.slack",
"typeVersion": 2.2,
"position": [920, 400],
"credentials": {"slackApi": {"id": "", "name": "Slack"}}
}
],
"connections": {
"Cron 8h (Seg-Sex)": {"main": [[{"node": "Dispatch Start", "type": "main", "index": 0}]]},
"Dispatch Start": {"main": [[{"node": "Dispatch Setup", "type": "main", "index": 0}]]},
"Dispatch Setup": {"main": [[{"node": "Notificar Slack", "type": "main", "index": 0}]]},
"Cron 18h (Seg-Sex)": {"main": [[{"node": "Dispatch Stop", "type": "main", "index": 0}]]},
"Dispatch Stop": {"main": [[{"node": "Notificar Slack", "type": "main", "index": 0}]]}
},
"pinData": {},
"settings": {"executionOrder": "v1"},
"meta": {"templateCredsSetupCompleted": true},
"staticData": null,
"tags": [],
"triggerCount": 2
}Resultado
- ✅ EC2 liga 08:00 e UserData configura tudo automaticamente
- ✅ EC2 desliga 18:00
- ✅ OIDC — sem access keys expostas
- ✅ Slack notifica cada acao
- ✅ Economia ~65% ($0 fora do horario comercial)
ec2:StartInstances, ec2:StopInstances, ec2:DescribeInstances e ec2:RunInstances (para setup).Desafios Campo de Batalha
Labs rápidos do dia a dia — problemas reais que você vai enfrentar
🐳Deploy Docker no ECS Fargate
Médio 25 minECS • ECR • Fargate • ALB
Deploy Docker no ECS Fargate
Diagrama Animado
Objetivo
Fazer deploy de um container Docker no ECS Fargate com load balancer.
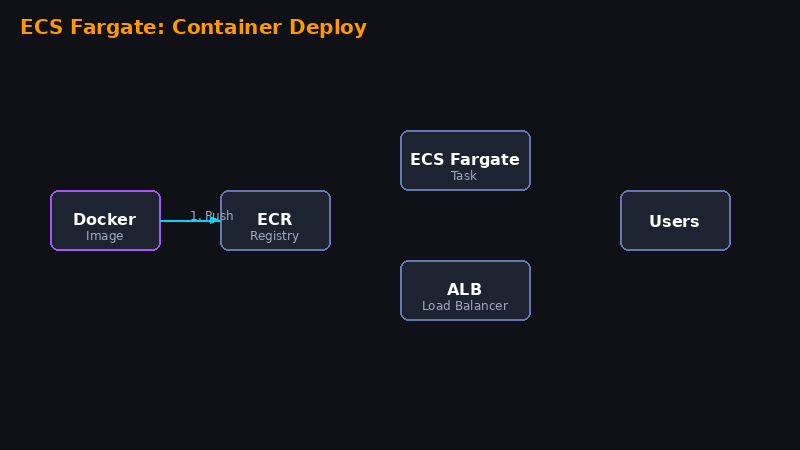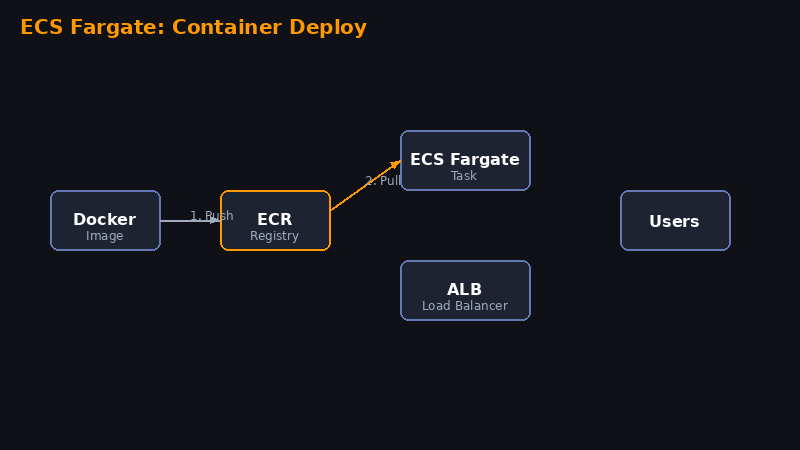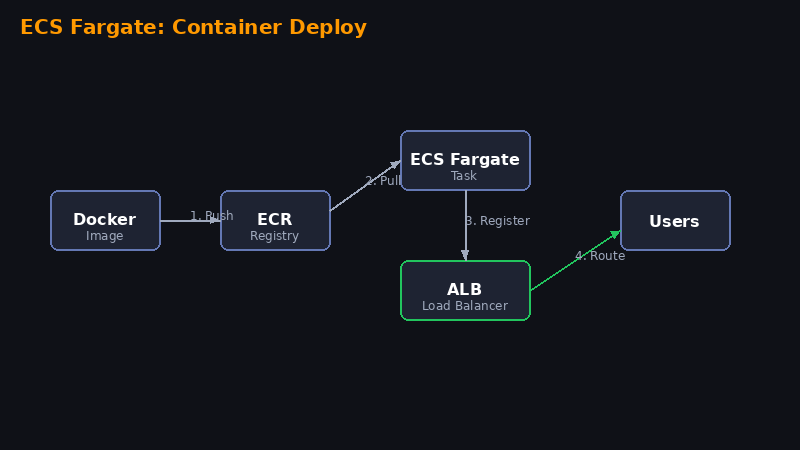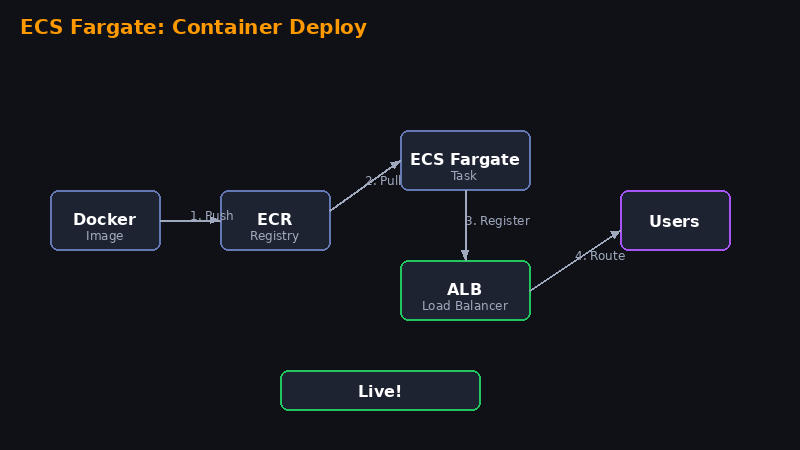
Passo 1 — Criar repositório ECR e push da imagem
aws ecr create-repository --repository-name myapp
aws ecr get-login-password | docker login --username AWS --password-stdin 123456789.dkr.ecr.us-east-1.amazonaws.com
docker build -t myapp .
docker tag myapp:latest 123456789.dkr.ecr.us-east-1.amazonaws.com/myapp:latest
docker push 123456789.dkr.ecr.us-east-1.amazonaws.com/myapp:latestPasso 2 — Criar Cluster ECS
ECS → Create Cluster → AWS Fargate → nome: prod-cluster
Passo 3 — Criar Task Definition
ECS → Task Definitions → Create → Fargate. Container: imagem do ECR, porta 3000, 512 CPU, 1024 Memory.
Passo 4 — Criar Service com ALB
No cluster → Create Service → Launch type Fargate → desired tasks: 2 → Create ALB → target group porta 3000.
Passo 5 — Testar
curl http://seu-alb-dns.us-east-1.elb.amazonaws.comaws ecs update-service --force-new-deployment para forçar redeploy após push de nova imagem.📊CloudWatch Dashboard + Alarmes de Billing
Fácil 15 minCloudWatch • SNS • Billing • FinOps
CloudWatch Dashboard + Alarmes de Billing
Objetivo
Criar um alarme que te avisa por email quando sua conta AWS ultrapassar um valor definido. Ao final, você terá monitoramento de custos ativo com notificação automática.
Pré-requisitos
- AWS CLI configurado
- Acesso à região
us-east-1(billing metrics só existem lá)
Passo 1 — Habilitar Billing Alerts
Acesse o console AWS → Billing → Billing Preferences → marque Receive Billing Alerts e salve.
Passo 2 — Criar tópico SNS para notificações
# Criar tópico
aws sns create-topic --name billing-alerts --region us-east-1
# Anotar o TopicArn retornado
# arn:aws:sns:us-east-1:ACCOUNT_ID:billing-alerts
# Inscrever seu email
aws sns subscribe \
--topic-arn arn:aws:sns:us-east-1:$(aws sts get-caller-identity --query Account --output text):billing-alerts \
--protocol email \
--notification-endpoint seuemail@gmail.com \
--region us-east-1✅ Validação: Verifique seu email e confirme a inscrição (clique no link "Confirm subscription").
# Verificar status
aws sns list-subscriptions-by-topic \
--topic-arn arn:aws:sns:us-east-1:$(aws sts get-caller-identity --query Account --output text):billing-alerts \
--region us-east-1 \
--query 'Subscriptions[0].SubscriptionArn'
# Deve mostrar o ARN (não "PendingConfirmation")Passo 3 — Criar alarme de billing
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
aws cloudwatch put-metric-alarm \
--alarm-name "billing-acima-50-usd" \
--alarm-description "Alerta quando conta passar de 50 USD" \
--metric-name EstimatedCharges \
--namespace AWS/Billing \
--statistic Maximum \
--period 21600 \
--threshold 50 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:us-east-1:${ACCOUNT_ID}:billing-alerts \
--dimensions Name=Currency,Value=USD \
--region us-east-1✅ Validação:
aws cloudwatch describe-alarms \
--alarm-names "billing-acima-50-usd" \
--region us-east-1 \
--query 'MetricAlarms[0].{State:StateValue,Threshold:Threshold}'
# Deve retornar State: OK ou INSUFFICIENT_DATA, Threshold: 50.0Passo 4 — Criar alarmes adicionais (opcional)
# Alarme de 20 USD (aviso antecipado)
aws cloudwatch put-metric-alarm \
--alarm-name "billing-acima-20-usd" \
--metric-name EstimatedCharges \
--namespace AWS/Billing \
--statistic Maximum \
--period 21600 \
--threshold 20 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:us-east-1:${ACCOUNT_ID}:billing-alerts \
--dimensions Name=Currency,Value=USD \
--region us-east-1
# Alarme de 100 USD (crítico)
aws cloudwatch put-metric-alarm \
--alarm-name "billing-acima-100-usd" \
--metric-name EstimatedCharges \
--namespace AWS/Billing \
--statistic Maximum \
--period 21600 \
--threshold 100 \
--comparison-operator GreaterThanThreshold \
--evaluation-periods 1 \
--alarm-actions arn:aws:sns:us-east-1:${ACCOUNT_ID}:billing-alerts \
--dimensions Name=Currency,Value=USD \
--region us-east-1Passo 5 — Verificar no Console
CloudWatch → Alarms → verifique que os alarmes aparecem com estado OK ou INSUFFICIENT_DATA (normal nas primeiras 6h).
🛡️WAF + CloudFront: Proteger site contra ataques
Médio 30 minWAF • CloudFront • Rate Limiting • Geo Block
WAF + CloudFront: Proteger site contra ataques
Objetivo
Proteger sua aplicação web contra ataques DDoS, SQL injection, XSS e bots maliciosos usando WAF + CloudFront. Ao final, seu site terá proteção enterprise com rate limiting e geo blocking.
Pré-requisitos
- Uma distribuição CloudFront existente (ou site hospedado na AWS)
- AWS CLI configurado
Passo 1 — Criar Web ACL
# Web ACL precisa ser criada em us-east-1 para CloudFront
aws wafv2 create-web-acl \
--name protect-site \
--scope CLOUDFRONT \
--default-action Allow={} \
--visibility-config SampledRequestsEnabled=true,CloudWatchMetricsEnabled=true,MetricName=protect-site \
--region us-east-1 \
--query 'Summary.ARN' --output text✅ Validação:
aws wafv2 list-web-acls --scope CLOUDFRONT --region us-east-1 \
--query 'WebACLs[?Name==`protect-site`].ARN' --output textPasso 2 — Adicionar regras managed (OWASP Top 10)
Vá ao console: WAF → Web ACLs → protect-site → Rules → Add managed rule groups:
- AWS-AWSManagedRulesCommonRuleSet — protege contra OWASP Top 10 (XSS, path traversal, etc)
- AWS-AWSManagedRulesKnownBadInputsRuleSet — bloqueia payloads maliciosos conhecidos
- AWS-AWSManagedRulesSQLiRuleSet — bloqueia SQL injection
- AWS-AWSManagedRulesAmazonIpReputationList — bloqueia IPs com má reputação
Passo 3 — Criar regra de Rate Limiting
Bloqueia IPs que fazem muitas requisições (proteção contra DDoS/brute force):
WAF → Web ACL → Rules → Add my own rule → Rate-based rule:
- Rate limit: 2000 requests por 5 minutos por IP
- Action: Block
Passo 4 — Geo Blocking (opcional)
Se seu público é só Brasil, bloqueie países que não são relevantes:
WAF → Rules → Add rule → Geographic match → bloquear países que geram apenas tráfego malicioso.
Passo 5 — Associar ao CloudFront
WAF → Web ACL → Associated resources → Add → selecione sua distribuição CloudFront.
✅ Validação:
# Testar se WAF está ativo - fazer muitas requests rápidas
for i in $(seq 1 50); do curl -s -o /dev/null -w "%{http_code}\n" https://seusite.com/; done
# Se rate limit funciona, vai começar a retornar 403 após muitas requestsPasso 6 — Monitorar
# Ver métricas do WAF
aws cloudwatch get-metric-statistics \
--namespace AWS/WAFV2 \
--metric-name BlockedRequests \
--dimensions Name=WebACL,Value=protect-site Name=Rule,Value=ALL \
--start-time $(date -u -d '1 hour ago' +%Y-%m-%dT%H:%M:%S) \
--end-time $(date -u +%Y-%m-%dT%H:%M:%S) \
--period 300 --statistics Sum \
--region us-east-1🔄CI/CD com GitHub Actions → ECR → ECS
Médio 35 minGitHub Actions • ECR • ECS • Docker
CI/CD com GitHub Actions → ECR → ECS
Objetivo
Criar um pipeline CI/CD completo: push no GitHub → build da imagem Docker → push para ECR → deploy automático no ECS. Zero downtime com rolling update.
Pré-requisitos
- Repositório no GitHub com Dockerfile
- Cluster ECS com service rodando (veja lab ECS Fargate)
- Repositório ECR criado
Passo 1 — Criar IAM User para GitHub Actions
# Criar policy com permissões mínimas
cat > github-actions-policy.json << 'EOF'
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage",
"ecr:PutImage",
"ecr:InitiateLayerUpload",
"ecr:UploadLayerPart",
"ecr:CompleteLayerUpload"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ecs:UpdateService",
"ecs:DescribeServices",
"ecs:DescribeTaskDefinition",
"ecs:RegisterTaskDefinition"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::*:role/ecsTaskExecutionRole"
}
]
}
EOF
aws iam create-policy \
--policy-name GitHubActionsECS \
--policy-document file://github-actions-policy.json
# Criar user
aws iam create-user --user-name github-actions-ecs
aws iam attach-user-policy \
--user-name github-actions-ecs \
--policy-arn arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):policy/GitHubActionsECS
# Criar access key
aws iam create-access-key --user-name github-actions-ecs
# ANOTE o AccessKeyId e SecretAccessKeyPasso 2 — Configurar Secrets no GitHub
No repositório GitHub → Settings → Secrets and variables → Actions → New repository secret:
AWS_ACCESS_KEY_ID— AccessKeyId do passo anteriorAWS_SECRET_ACCESS_KEY— SecretAccessKeyAWS_REGION— ex: us-east-1ECR_REPOSITORY— nome do repo ECRECS_CLUSTER— nome do clusterECS_SERVICE— nome do service
Passo 3 — Criar workflow GitHub Actions
Crie o arquivo .github/workflows/deploy.yml:
name: Deploy to ECS
on:
push:
branches: [main]
env:
AWS_REGION: ${{ secrets.AWS_REGION }}
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v4
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ env.AWS_REGION }}
- name: Login to ECR
id: ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Build and push image
env:
ECR_REGISTRY: ${{ steps.ecr.outputs.registry }}
IMAGE_TAG: ${{ github.sha }}
run: |
docker build -t $ECR_REGISTRY/${{ secrets.ECR_REPOSITORY }}:$IMAGE_TAG .
docker push $ECR_REGISTRY/${{ secrets.ECR_REPOSITORY }}:$IMAGE_TAG
- name: Deploy to ECS
run: |
aws ecs update-service \
--cluster ${{ secrets.ECS_CLUSTER }} \
--service ${{ secrets.ECS_SERVICE }} \
--force-new-deploymentPasso 4 — Testar o pipeline
# Faça um commit e push
git add .
git commit -m "feat: trigger deploy"
git push origin main✅ Validação:
- GitHub → Actions → verifique que o workflow rodou com sucesso (check verde)
- ECR → verifique nova imagem com tag do commit SHA
- ECS → verifique que o service está fazendo rolling update
aws ecs describe-services \
--cluster SEU_CLUSTER \
--services SEU_SERVICE \
--query 'services[0].deployments[*].{status:status,running:runningCount,desired:desiredCount}'github.sha como image tag para rastreabilidade. Cada deploy tem uma imagem única vinculada ao commit.🔐IAM Policies: Least Privilege na prática
Médio 20 minIAM • Policies • SCP • Permission Boundary
IAM Policies: Least Privilege na prática
Objetivo
Implementar IAM com least privilege na prática — criar policies granulares, usar Permission Boundaries, e auditar permissões excessivas. Ao final, sua conta estará mais segura.
Pré-requisitos
- AWS CLI configurado com acesso admin
- Conta AWS com alguns recursos criados
Passo 1 — Auditar permissões atuais
# Listar users e suas policies
aws iam list-users --query 'Users[*].UserName' --output table
# Ver policies de um user
aws iam list-attached-user-policies --user-name NOME_USER
aws iam list-user-policies --user-name NOME_USER
# Verificar se alguém tem AdministratorAccess (PERIGO!)
aws iam list-entities-for-policy \
--policy-arn arn:aws:iam::aws:policy/AdministratorAccess \
--query '{Users:PolicyUsers[*].UserName,Roles:PolicyRoles[*].RoleName}'Passo 2 — Criar policy granular (exemplo: dev backend)
cat > dev-backend-policy.json << 'EOF'
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LambdaReadDeploy",
"Effect": "Allow",
"Action": [
"lambda:GetFunction",
"lambda:ListFunctions",
"lambda:UpdateFunctionCode",
"lambda:InvokeFunction"
],
"Resource": "arn:aws:lambda:*:*:function:app-*"
},
{
"Sid": "DynamoDBAccess",
"Effect": "Allow",
"Action": [
"dynamodb:GetItem",
"dynamodb:PutItem",
"dynamodb:Query",
"dynamodb:Scan",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem"
],
"Resource": "arn:aws:dynamodb:*:*:table/app-*"
},
{
"Sid": "CloudWatchLogs",
"Effect": "Allow",
"Action": [
"logs:GetLogEvents",
"logs:FilterLogEvents",
"logs:DescribeLogGroups"
],
"Resource": "*"
},
{
"Sid": "DenyDangerous",
"Effect": "Deny",
"Action": [
"iam:*",
"organizations:*",
"ec2:TerminateInstances",
"rds:DeleteDBInstance"
],
"Resource": "*"
}
]
}
EOF
aws iam create-policy \
--policy-name DevBackendLeastPrivilege \
--policy-document file://dev-backend-policy.json✅ Validação: Simular se a policy funciona:
aws iam simulate-principal-policy \
--policy-source-arn arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):user/dev-user \
--action-names lambda:InvokeFunction dynamodb:PutItem iam:CreateUser \
--query 'EvaluationResults[*].{Action:EvalActionName,Decision:EvalDecision}'Passo 3 — Criar Permission Boundary
Permission Boundary limita o máximo que qualquer policy pode conceder:
cat > boundary-policy.json << 'EOF'
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:*",
"dynamodb:*",
"s3:*",
"logs:*",
"cloudwatch:*",
"apigateway:*",
"sqs:*",
"sns:*"
],
"Resource": "*"
},
{
"Effect": "Deny",
"Action": [
"iam:CreateUser",
"iam:DeleteUser",
"iam:AttachUserPolicy",
"organizations:*",
"account:*"
],
"Resource": "*"
}
]
}
EOF
aws iam create-policy \
--policy-name DevPermissionBoundary \
--policy-document file://boundary-policy.json
# Aplicar boundary ao user
aws iam put-user-permissions-boundary \
--user-name dev-user \
--permissions-boundary arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):policy/DevPermissionBoundaryPasso 4 — Gerar policy baseada em uso real
# IAM Access Analyzer gera policy baseada no que o user realmente usou nos últimos 90 dias
aws accessanalyzer start-policy-generation \
--policy-generation-details '{"principalArn":"arn:aws:iam::ACCOUNT:user/dev-user"}' \
--region us-east-1Action: "*" ou Resource: "*" em produção. Sempre especifique ARNs com prefixo do projeto (ex: arn:aws:lambda:*:*:function:app-*).🗄️S3 Lifecycle Policies: Economizar com classes de storage
Fácil 15 minS3 • Lifecycle • Glacier • FinOps
S3 Lifecycle Policies: Economizar com classes de storage
Objetivo
Configurar Lifecycle Policies no S3 para mover objetos automaticamente entre classes de storage e economizar até 80% em custos de armazenamento.
Passo 1 — Entender as classes de storage
- S3 Standard — acesso frequente ($0.023/GB)
- S3 Infrequent Access — acesso raro ($0.0125/GB, -46%)
- S3 Glacier Instant — arquivo com acesso imediato ($0.004/GB, -82%)
- S3 Glacier Deep Archive — arquivo longo prazo ($0.00099/GB, -96%)
Passo 2 — Criar bucket de teste
BUCKET="lifecycle-lab-$(date +%s)"
aws s3 mb s3://$BUCKET --region us-east-1
echo "Bucket: $BUCKET"Passo 3 — Criar Lifecycle Policy
cat > lifecycle.json << 'EOF'
{
"Rules": [
{
"ID": "MoveToIA30days",
"Status": "Enabled",
"Filter": {"Prefix": ""},
"Transitions": [
{"Days": 30, "StorageClass": "STANDARD_IA"},
{"Days": 90, "StorageClass": "GLACIER_IR"},
{"Days": 180, "StorageClass": "DEEP_ARCHIVE"}
],
"Expiration": {"Days": 365},
"NoncurrentVersionTransitions": [
{"NoncurrentDays": 7, "StorageClass": "GLACIER_IR"}
],
"NoncurrentVersionExpiration": {"NoncurrentDays": 30}
}
]
}
EOF
aws s3api put-bucket-lifecycle-configuration \
--bucket $BUCKET \
--lifecycle-configuration file://lifecycle.json✅ Validação:
aws s3api get-bucket-lifecycle-configuration --bucket $BUCKET \
--query 'Rules[0].{ID:ID,Transitions:Transitions}'Passo 4 — Simular economia
Para 1TB de dados:
- Tudo em Standard: $23.55/mês
- Com lifecycle (30d→IA, 90d→Glacier): ~$5/mês
- Economia: ~$18/mês = $220/ano
🧹 Cleanup
aws s3 rb s3://$BUCKET --force📧Lambda + SES: Envio de emails automático
Médio 25 minLambda • SES • EventBridge • Cron
Lambda + SES: Envio de emails automático
Objetivo
Criar uma Lambda que envia emails automáticos via SES, disparada por um cron (EventBridge). Útil para relatórios diários, alertas, ou newsletters.
Passo 1 — Verificar identidade no SES
# Verificar email do remetente
aws ses verify-email-identity \
--email-address seuemail@gmail.com \
--region us-east-1
# Confirme clicando no link que chegar no email
# Verificar status
aws ses get-identity-verification-attributes \
--identities seuemail@gmail.com \
--region us-east-1 \
--query 'VerificationAttributes.*.VerificationStatus'Passo 2 — Criar a função Lambda
mkdir lambda-email && cd lambda-email
cat > index.mjs << 'EOF'
import { SESClient, SendEmailCommand } from "@aws-sdk/client-ses";
const ses = new SESClient({ region: "us-east-1" });
export const handler = async (event) => {
const params = {
Source: process.env.FROM_EMAIL,
Destination: { ToAddresses: [process.env.TO_EMAIL] },
Message: {
Subject: { Data: "Relatorio Diario - " + new Date().toLocaleDateString("pt-BR") },
Body: {
Html: { Data: "Relatorio Diario
Tudo operacional. Gerado em: " + new Date().toISOString() + "
" }
}
}
};
await ses.send(new SendEmailCommand(params));
return { statusCode: 200, body: "Email enviado!" };
};
EOF
zip function.zip index.mjsPasso 3 — Criar IAM Role para Lambda
aws iam create-role \
--role-name lambda-ses-role \
--assume-role-policy-document '{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Principal":{"Service":"lambda.amazonaws.com"},"Action":"sts:AssumeRole"}]}'
aws iam attach-role-policy --role-name lambda-ses-role \
--policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
aws iam put-role-policy --role-name lambda-ses-role \
--policy-name ses-send \
--policy-document '{"Version":"2012-10-17","Statement":[{"Effect":"Allow","Action":"ses:SendEmail","Resource":"*"}]}'
sleep 10 # aguardar propagaçãoPasso 4 — Deploy da Lambda
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
aws lambda create-function \
--function-name daily-email-report \
--runtime nodejs20.x \
--handler index.handler \
--zip-file fileb://function.zip \
--role arn:aws:iam::${ACCOUNT_ID}:role/lambda-ses-role \
--environment "Variables={FROM_EMAIL=seuemail@gmail.com,TO_EMAIL=seuemail@gmail.com}" \
--region us-east-1✅ Validação: Testar manualmente:
aws lambda invoke --function-name daily-email-report \
--region us-east-1 /tmp/response.json && cat /tmp/response.json
# Verifique seu email - deve ter chegado o relatórioPasso 5 — Agendar com EventBridge (cron)
# Disparar todo dia às 8h (UTC)
aws events put-rule \
--name daily-email-8am \
--schedule-expression "cron(0 8 * * ? *)" \
--region us-east-1
aws lambda add-permission \
--function-name daily-email-report \
--statement-id eventbridge \
--action lambda:InvokeFunction \
--principal events.amazonaws.com \
--region us-east-1
aws events put-targets \
--rule daily-email-8am \
--targets "Id=1,Arn=arn:aws:lambda:us-east-1:${ACCOUNT_ID}:function:daily-email-report" \
--region us-east-1💾Backup automatizado RDS com retenção
Fácil 20 minRDS • Backup • Snapshot • Restore
Backup automatizado RDS com retenção
Objetivo
Configurar backup automatizado do RDS com retenção, snapshots manuais, e testar restore para garantir que seus dados estão seguros.
Passo 1 — Verificar configuração de backup atual
# Listar instâncias RDS
aws rds describe-db-instances \
--query 'DBInstances[*].{Name:DBInstanceIdentifier,Backup:BackupRetentionPeriod,Window:PreferredBackupWindow}' \
--output tablePasso 2 — Configurar backup automático (se não estiver)
# Habilitar backup com retenção de 7 dias
aws rds modify-db-instance \
--db-instance-identifier meu-banco \
--backup-retention-period 7 \
--preferred-backup-window "03:00-04:00" \
--apply-immediately✅ Validação:
aws rds describe-db-instances \
--db-instance-identifier meu-banco \
--query 'DBInstances[0].{Backup:BackupRetentionPeriod,Window:PreferredBackupWindow,Status:DBInstanceStatus}'Passo 3 — Criar snapshot manual
aws rds create-db-snapshot \
--db-instance-identifier meu-banco \
--db-snapshot-identifier meu-banco-$(date +%Y%m%d)
# Aguardar conclusão
aws rds wait db-snapshot-available \
--db-snapshot-identifier meu-banco-$(date +%Y%m%d)
echo "Snapshot criado com sucesso!"✅ Validação:
aws rds describe-db-snapshots \
--db-snapshot-identifier meu-banco-$(date +%Y%m%d) \
--query 'DBSnapshots[0].{Status:Status,Size:AllocatedStorage,Created:SnapshotCreateTime}'Passo 4 — Testar restore (IMPORTANTE!)
# Restore cria uma NOVA instância a partir do snapshot
aws rds restore-db-instance-from-db-snapshot \
--db-instance-identifier meu-banco-restore-test \
--db-snapshot-identifier meu-banco-$(date +%Y%m%d) \
--db-instance-class db.t3.micro
# Aguardar ficar disponível (~5-10 min)
aws rds wait db-instance-available \
--db-instance-identifier meu-banco-restore-test
# Verificar endpoint
aws rds describe-db-instances \
--db-instance-identifier meu-banco-restore-test \
--query 'DBInstances[0].Endpoint.Address'Passo 5 — Cleanup do teste
# Deletar instância de teste (sem snapshot final)
aws rds delete-db-instance \
--db-instance-identifier meu-banco-restore-test \
--skip-final-snapshot🔍CloudTrail: Auditoria completa da conta
Fácil 20 minCloudTrail • S3 • Athena • Compliance
CloudTrail: Auditoria completa da conta
Objetivo
Configurar CloudTrail para auditoria completa da conta — saber quem fez o quê, quando, e de onde. Essencial para compliance e investigação de incidentes.
Passo 1 — Criar bucket S3 para logs
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
BUCKET="cloudtrail-logs-${ACCOUNT_ID}"
aws s3 mb s3://$BUCKET --region us-east-1
# Policy para CloudTrail escrever no bucket
cat > bucket-policy.json << EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {"Service": "cloudtrail.amazonaws.com"},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::${BUCKET}"
},
{
"Effect": "Allow",
"Principal": {"Service": "cloudtrail.amazonaws.com"},
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::${BUCKET}/AWSLogs/${ACCOUNT_ID}/*",
"Condition": {"StringEquals": {"s3:x-amz-acl": "bucket-owner-full-control"}}
}
]
}
EOF
aws s3api put-bucket-policy --bucket $BUCKET --policy file://bucket-policy.jsonPasso 2 — Criar Trail
aws cloudtrail create-trail \
--name main-trail \
--s3-bucket-name $BUCKET \
--is-multi-region-trail \
--enable-log-file-validation \
--region us-east-1
# Ativar o trail
aws cloudtrail start-logging --name main-trail --region us-east-1✅ Validação:
aws cloudtrail get-trail-status --name main-trail --region us-east-1 \
--query '{Logging:IsLogging,LastDelivery:LatestDeliveryTime}'Passo 3 — Consultar eventos recentes
# Últimos 10 eventos
aws cloudtrail lookup-events \
--max-results 10 \
--region us-east-1 \
--query 'Events[*].{Time:EventTime,User:Username,Action:EventName,Source:EventSource}' \
--output table
# Filtrar por usuário específico
aws cloudtrail lookup-events \
--lookup-attributes AttributeKey=Username,AttributeValue=admin \
--max-results 5 --region us-east-1 \
--query 'Events[*].{Time:EventTime,Action:EventName}'Passo 4 — Investigar ação específica
# Quem deletou um recurso?
aws cloudtrail lookup-events \
--lookup-attributes AttributeKey=EventName,AttributeValue=DeleteBucket \
--region us-east-1 \
--query 'Events[*].{Time:EventTime,User:Username,IP:CloudTrailEvent}' \
--output jsonPasso 5 — Consultar com Athena (logs antigos)
Para logs com mais de 90 dias, use Athena para consultar diretamente no S3:
# Criar tabela no Athena (execute no console Athena)
CREATE EXTERNAL TABLE cloudtrail_logs (
eventTime STRING, eventSource STRING, eventName STRING,
userIdentity STRUCT,
sourceIPAddress STRING, requestParameters STRING
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
LOCATION 's3://BUCKET/AWSLogs/ACCOUNT_ID/CloudTrail/'; 🔗Step Functions: Orquestrar workflows complexos
Avançado 40 minStep Functions • Lambda • SQS • Error Handling
Step Functions: Orquestrar workflows complexos
Objetivo
Criar um workflow com Step Functions que orquestra múltiplas Lambdas com tratamento de erro, retry e paralelismo. Ideal para processos de negócio complexos.
Passo 1 — Criar Lambdas do workflow
# Lambda 1: Validar pedido
cat > validate.py << 'EOF'
def handler(event, context):
if not event.get('orderId'):
raise Exception("orderId obrigatorio")
return {"orderId": event['orderId'], "status": "validated", "amount": event.get('amount', 0)}
EOF
zip validate.zip validate.py
aws lambda create-function --function-name sf-validate --runtime python3.12 --handler validate.handler --zip-file fileb://validate.zip --role arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):role/lambda-basic-role --region us-east-1
# Lambda 2: Processar pagamento
cat > payment.py << 'EOF'
import random
def handler(event, context):
if random.random() < 0.3:
raise Exception("Payment gateway timeout")
return {**event, "status": "paid", "transactionId": "TXN-" + str(random.randint(1000,9999))}
EOF
zip payment.zip payment.py
aws lambda create-function --function-name sf-payment --runtime python3.12 --handler payment.handler --zip-file fileb://payment.zip --role arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):role/lambda-basic-role --region us-east-1
# Lambda 3: Enviar confirmacao
cat > notify.py << 'EOF'
def handler(event, context):
print(f"Email enviado para pedido {event['orderId']}")
return {**event, "status": "notified"}
EOF
zip notify.zip notify.py
aws lambda create-function --function-name sf-notify --runtime python3.12 --handler notify.handler --zip-file fileb://notify.zip --role arn:aws:iam::$(aws sts get-caller-identity --query Account --output text):role/lambda-basic-role --region us-east-1Passo 2 — Criar State Machine
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
cat > state-machine.json << EOF
{
"Comment": "Workflow de processamento de pedido",
"StartAt": "ValidarPedido",
"States": {
"ValidarPedido": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:${ACCOUNT_ID}:function:sf-validate",
"Next": "ProcessarPagamento",
"Catch": [{"ErrorEquals": ["States.ALL"], "Next": "PedidoFalhou"}]
},
"ProcessarPagamento": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:${ACCOUNT_ID}:function:sf-payment",
"Retry": [{"ErrorEquals": ["States.ALL"], "MaxAttempts": 3, "IntervalSeconds": 2, "BackoffRate": 2}],
"Next": "EnviarConfirmacao",
"Catch": [{"ErrorEquals": ["States.ALL"], "Next": "PedidoFalhou"}]
},
"EnviarConfirmacao": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:${ACCOUNT_ID}:function:sf-notify",
"End": true
},
"PedidoFalhou": {
"Type": "Fail",
"Error": "ProcessamentoFalhou",
"Cause": "Erro no processamento do pedido"
}
}
}
EOF
aws stepfunctions create-state-machine \
--name pedido-workflow \
--definition file://state-machine.json \
--role-arn arn:aws:iam::${ACCOUNT_ID}:role/StepFunctionsExecutionRole \
--region us-east-1Passo 3 — Executar e testar
# Executar com sucesso
aws stepfunctions start-execution \
--state-machine-arn arn:aws:states:us-east-1:${ACCOUNT_ID}:stateMachine:pedido-workflow \
--input '{"orderId": "ORD-001", "amount": 99.90}' \
--region us-east-1
# Executar com erro (sem orderId)
aws stepfunctions start-execution \
--state-machine-arn arn:aws:states:us-east-1:${ACCOUNT_ID}:stateMachine:pedido-workflow \
--input '{"amount": 50}' \
--region us-east-1✅ Validação: Veja no console Step Functions → Executions → clique na execução para ver o fluxo visual com cada estado.
🌍Route53 + CloudFront: Site com domínio custom + SSL
Médio 30 minRoute53 • CloudFront • ACM • S3
Route53 + CloudFront: Site com domínio custom + SSL
Objetivo
Configurar um site com domínio customizado, HTTPS gratuito (ACM) e CDN global via CloudFront. Resultado: site rápido, seguro e com seu domínio.
Passo 1 — Solicitar certificado SSL (ACM)
# PRECISA ser em us-east-1 para CloudFront
aws acm request-certificate \
--domain-name seudominio.com.br \
--subject-alternative-names "*.seudominio.com.br" \
--validation-method DNS \
--region us-east-1 \
--query 'CertificateArn' --output textPasso 2 — Validar domínio via DNS
# Pegar o CNAME de validação
aws acm describe-certificate \
--certificate-arn ARN_DO_CERTIFICADO \
--region us-east-1 \
--query 'Certificate.DomainValidationOptions[0].ResourceRecord'
# Criar o registro CNAME no Route53
aws route53 change-resource-record-sets \
--hosted-zone-id SEU_ZONE_ID \
--change-batch '{
"Changes": [{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "_acme-challenge.seudominio.com.br",
"Type": "CNAME",
"TTL": 300,
"ResourceRecords": [{"Value": "VALOR_DO_ACM"}]
}
}]
}'
# Aguardar validação (~5 min)
aws acm wait certificate-validated \
--certificate-arn ARN_DO_CERTIFICADO --region us-east-1Passo 3 — Criar distribuição CloudFront
aws cloudfront create-distribution \
--origin-domain-name seusite.s3.amazonaws.com \
--default-root-object index.html \
--query 'Distribution.DomainName' --output text
# Para configuração completa com SSL e domínio custom,
# use o console: CloudFront → Create Distribution
# Origins: seu bucket S3 ou ALB
# Alternate domain: seudominio.com.br
# SSL Certificate: selecione o certificado ACM criado
# Viewer Protocol Policy: Redirect HTTP to HTTPSPasso 4 — Apontar domínio para CloudFront
# Criar registro A (Alias) no Route53
aws route53 change-resource-record-sets \
--hosted-zone-id SEU_ZONE_ID \
--change-batch '{
"Changes": [{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "seudominio.com.br",
"Type": "A",
"AliasTarget": {
"HostedZoneId": "Z2FDTNDATAQYW2",
"DNSName": "d1234567.cloudfront.net",
"EvaluateTargetHealth": false
}
}
}]
}'✅ Validação:
# Testar HTTPS
curl -I https://seudominio.com.br
# Deve retornar HTTP/2 200 com header "server: CloudFront"
# Verificar certificado
echo | openssl s_client -connect seudominio.com.br:443 2>/dev/null | grep "subject="Z2FDTNDATAQYW2 é o HostedZoneId fixo do CloudFront para registros Alias. Sempre use esse valor.📨SQS + Lambda: Processamento assíncrono
Médio 25 minSQS • Lambda • DLQ • Retry
SQS + Lambda: Processamento assíncrono
Objetivo
Criar um sistema de processamento assíncrono com SQS + Lambda: mensagens entram na fila e são processadas automaticamente. Com Dead Letter Queue para mensagens que falharem.
Passo 1 — Criar Dead Letter Queue (DLQ)
# DLQ recebe mensagens que falharam após N tentativas
aws sqs create-queue \
--queue-name orders-dlq \
--region us-east-1 \
--query 'QueueUrl' --output text
DLQ_ARN=$(aws sqs get-queue-attributes \
--queue-url $(aws sqs get-queue-url --queue-name orders-dlq --region us-east-1 --query 'QueueUrl' --output text) \
--attribute-names QueueArn --region us-east-1 \
--query 'Attributes.QueueArn' --output text)
echo "DLQ ARN: $DLQ_ARN"Passo 2 — Criar fila principal com DLQ
aws sqs create-queue \
--queue-name orders-queue \
--attributes '{
"VisibilityTimeout": "60",
"MessageRetentionPeriod": "86400",
"RedrivePolicy": "{"deadLetterTargetArn":"'$DLQ_ARN'","maxReceiveCount":"3"}"
}' \
--region us-east-1
QUEUE_URL=$(aws sqs get-queue-url --queue-name orders-queue --region us-east-1 --query 'QueueUrl' --output text)
echo "Queue URL: $QUEUE_URL"✅ Validação:
aws sqs get-queue-attributes --queue-url $QUEUE_URL \
--attribute-names RedrivePolicy VisibilityTimeout --region us-east-1Passo 3 — Criar Lambda processadora
cat > process.py << 'EOF'
import json
def handler(event, context):
for record in event['Records']:
body = json.loads(record['body'])
print(f"Processando pedido: {body['orderId']} - valor: {body['amount']}")
# Simular erro para testar DLQ
if body.get('forceError'):
raise Exception("Erro proposital para testar DLQ")
return {"statusCode": 200}
EOF
zip process.zip process.py
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
aws lambda create-function \
--function-name process-orders \
--runtime python3.12 \
--handler process.handler \
--zip-file fileb://process.zip \
--role arn:aws:iam::${ACCOUNT_ID}:role/lambda-basic-role \
--timeout 60 \
--region us-east-1Passo 4 — Conectar SQS → Lambda
QUEUE_ARN=$(aws sqs get-queue-attributes --queue-url $QUEUE_URL \
--attribute-names QueueArn --region us-east-1 --query 'Attributes.QueueArn' --output text)
aws lambda create-event-source-mapping \
--function-name process-orders \
--event-source-arn $QUEUE_ARN \
--batch-size 5 \
--region us-east-1Passo 5 — Testar
# Enviar mensagem normal
aws sqs send-message --queue-url $QUEUE_URL \
--message-body '{"orderId":"ORD-001","amount":99.90}' --region us-east-1
# Enviar mensagem que vai falhar (vai para DLQ após 3 tentativas)
aws sqs send-message --queue-url $QUEUE_URL \
--message-body '{"orderId":"ORD-002","amount":50,"forceError":true}' --region us-east-1
# Verificar DLQ após ~3 min
aws sqs get-queue-attributes \
--queue-url $(aws sqs get-queue-url --queue-name orders-dlq --region us-east-1 --query 'QueueUrl' --output text) \
--attribute-names ApproximateNumberOfMessages --region us-east-1🚪Cognito: Autenticação de usuários para sua API
Avançado 35 minCognito • API Gateway • JWT • OAuth
Cognito: Autenticação de usuários para sua API
Objetivo
Criar autenticação de usuários para sua API usando Cognito User Pool + API Gateway. Resultado: signup, login, JWT tokens, e proteção de endpoints.
Passo 1 — Criar User Pool
aws cognito-idp create-user-pool \
--pool-name app-users \
--auto-verified-attributes email \
--username-attributes email \
--policies '{"PasswordPolicy":{"MinimumLength":8,"RequireUppercase":true,"RequireLowercase":true,"RequireNumbers":true,"RequireSymbols":false}}' \
--region us-east-1 \
--query 'UserPool.Id' --output text
# Anotar o User Pool ID (ex: us-east-1_ABC123)Passo 2 — Criar App Client
POOL_ID="us-east-1_SEU_POOL_ID"
aws cognito-idp create-user-pool-client \
--user-pool-id $POOL_ID \
--client-name app-web \
--explicit-auth-flows ALLOW_USER_PASSWORD_AUTH ALLOW_REFRESH_TOKEN_AUTH \
--generate-secret \
--region us-east-1 \
--query 'UserPoolClient.ClientId' --output text
# Anotar o Client IDPasso 3 — Registrar usuário
CLIENT_ID="SEU_CLIENT_ID"
aws cognito-idp sign-up \
--client-id $CLIENT_ID \
--username usuario@email.com \
--password "MinhaSenh@123" \
--user-attributes Name=email,Value=usuario@email.com \
--region us-east-1
# Confirmar (admin, sem precisar do código)
aws cognito-idp admin-confirm-sign-up \
--user-pool-id $POOL_ID \
--username usuario@email.com \
--region us-east-1Passo 4 — Fazer login e obter token
aws cognito-idp initiate-auth \
--client-id $CLIENT_ID \
--auth-flow USER_PASSWORD_AUTH \
--auth-parameters USERNAME=usuario@email.com,PASSWORD="MinhaSenh@123" \
--region us-east-1 \
--query 'AuthenticationResult.{AccessToken:AccessToken,IdToken:IdToken,ExpiresIn:ExpiresIn}'✅ Validação: Decodificar o JWT:
# Copie o IdToken e decodifique (base64)
echo "SEU_ID_TOKEN" | cut -d. -f2 | base64 -d 2>/dev/null | python3 -m json.toolPasso 5 — Proteger API Gateway com Cognito
No console API Gateway:
- Authorizers → Create → Cognito → selecione seu User Pool
- No método (GET, POST) → Method Request → Authorization → selecione o authorizer
# Testar endpoint protegido
TOKEN="SEU_ID_TOKEN"
curl -H "Authorization: $TOKEN" https://sua-api.execute-api.us-east-1.amazonaws.com/prod/recurso📈Auto Scaling EC2 com Target Tracking
Médio 30 minEC2 • Auto Scaling • ALB • CloudWatch
Auto Scaling EC2 com Target Tracking
Objetivo
Configurar Auto Scaling com Target Tracking para que suas EC2 escalem automaticamente baseado em CPU. Resultado: alta disponibilidade com custo otimizado.
Passo 1 — Criar Launch Template
aws ec2 create-launch-template \
--launch-template-name app-template \
--version-description "v1" \
--launch-template-data '{
"ImageId": "ami-0c02fb55956c7d316",
"InstanceType": "t3.micro",
"SecurityGroupIds": ["sg-XXXXX"],
"UserData": "'$(echo '#!/bin/bash
yum install -y httpd
systemctl start httpd
echo "Host: $(hostname)" > /var/www/html/index.html' | base64)'"
}' --region us-east-1Passo 2 — Criar Auto Scaling Group
# Pegar subnets
SUBNETS=$(aws ec2 describe-subnets --filters Name=default-for-az,Values=true \
--query 'Subnets[*].SubnetId' --output text --region us-east-1 | tr '\t' ',')
aws autoscaling create-auto-scaling-group \
--auto-scaling-group-name app-asg \
--launch-template LaunchTemplateName=app-template,Version='$Latest' \
--min-size 1 \
--max-size 4 \
--desired-capacity 2 \
--vpc-zone-identifier "$SUBNETS" \
--health-check-type ELB \
--health-check-grace-period 120 \
--region us-east-1Passo 3 — Configurar Target Tracking (CPU 60%)
aws autoscaling put-scaling-policy \
--auto-scaling-group-name app-asg \
--policy-name cpu-target-60 \
--policy-type TargetTrackingScaling \
--target-tracking-configuration '{
"PredefinedMetricSpecification": {"PredefinedMetricType": "ASGAverageCPUUtilization"},
"TargetValue": 60.0,
"ScaleInCooldown": 300,
"ScaleOutCooldown": 60
}' --region us-east-1✅ Validação:
aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-names app-asg --region us-east-1 \
--query 'AutoScalingGroups[0].{Min:MinSize,Max:MaxSize,Desired:DesiredCapacity,Instances:Instances[*].InstanceId}'Passo 4 — Testar scale-out (stress test)
# Conectar numa instância e gerar carga
INSTANCE_ID=$(aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-names app-asg --region us-east-1 \
--query 'AutoScalingGroups[0].Instances[0].InstanceId' --output text)
# Via SSM (sem SSH)
aws ssm send-command \
--instance-ids $INSTANCE_ID \
--document-name AWS-RunShellScript \
--parameters 'commands=["stress --cpu 4 --timeout 300"]' \
--region us-east-1
# Monitorar scaling (aguardar ~2 min)
watch -n 10 "aws autoscaling describe-auto-scaling-groups \
--auto-scaling-group-names app-asg --region us-east-1 \
--query 'AutoScalingGroups[0].{Desired:DesiredCapacity,Instances:length(Instances)}'"🧹 Cleanup
aws autoscaling delete-auto-scaling-group --auto-scaling-group-name app-asg --force-delete --region us-east-1
aws ec2 delete-launch-template --launch-template-name app-template --region us-east-1🔒S3 Bucket Policy: Acesso cross-account seguro
Médio 20 minS3 • Bucket Policy • Cross-Account • KMS
S3 Bucket Policy: Acesso cross-account seguro
Objetivo
Configurar acesso cross-account seguro a um bucket S3 — permitir que outra conta AWS acesse seus dados sem compartilhar credenciais.
Passo 1 — Criar bucket na Conta A (dona dos dados)
BUCKET="cross-account-data-$(date +%s)"
aws s3 mb s3://$BUCKET --region us-east-1
# Upload de arquivo de teste
echo "dados confidenciais" | aws s3 cp - s3://$BUCKET/dados.txtPasso 2 — Criar Bucket Policy permitindo Conta B
CONTA_B_ID="123456789012" # ID da conta que vai acessar
cat > bucket-policy.json << EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "CrossAccountRead",
"Effect": "Allow",
"Principal": {"AWS": "arn:aws:iam::${CONTA_B_ID}:root"},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::${BUCKET}",
"arn:aws:s3:::${BUCKET}/*"
]
}
]
}
EOF
aws s3api put-bucket-policy --bucket $BUCKET --policy file://bucket-policy.json✅ Validação (na Conta A):
aws s3api get-bucket-policy --bucket $BUCKET --query 'Policy' --output text | python3 -m json.toolPasso 3 — Na Conta B: criar role para acessar
# Na Conta B, criar role que assume acesso
cat > trust.json << 'EOF'
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"AWS": "arn:aws:iam::CONTA_B_ID:user/dev-user"},
"Action": "sts:AssumeRole"
}]
}
EOF
# Policy de acesso ao bucket
cat > s3-access.json << EOF
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:ListBucket"],
"Resource": ["arn:aws:s3:::${BUCKET}", "arn:aws:s3:::${BUCKET}/*"]
}]
}
EOFPasso 4 — Testar acesso da Conta B
# Da Conta B, acessar o bucket da Conta A
aws s3 ls s3://$BUCKET/ --region us-east-1
aws s3 cp s3://$BUCKET/dados.txt -
# Tentar escrever (deve falhar - só tem permissão de leitura)
echo "teste" | aws s3 cp - s3://$BUCKET/hack.txt
# AccessDenied - correto!Passo 5 — Adicionar criptografia (KMS cross-account)
# Para dados sensíveis, use KMS com key policy cross-account
aws s3api put-bucket-encryption \
--bucket $BUCKET \
--server-side-encryption-configuration '{
"Rules": [{"ApplyServerSideEncryptionByDefault": {"SSEAlgorithm": "aws:kms"}}]
}'"Principal": "*" em bucket policies! Sempre especifique o Account ID exato.🏗️Terraform: Infraestrutura como Código básico
Médio 45 minTerraform • IaC • VPC • EC2
Terraform: Infraestrutura como Código básico
Objetivo
Criar infraestrutura AWS com Terraform — VPC, subnet, security group e EC2. Entender o ciclo plan → apply → destroy.
Passo 1 — Instalar Terraform
# Linux/Mac
curl -fsSL https://releases.hashicorp.com/terraform/1.7.0/terraform_1.7.0_linux_amd64.zip -o tf.zip
unzip tf.zip && sudo mv terraform /usr/local/bin/
terraform versionPasso 2 — Criar estrutura do projeto
mkdir terraform-lab && cd terraform-lab
cat > main.tf << 'EOF'
terraform {
required_providers {
aws = { source = "hashicorp/aws", version = "~> 5.0" }
}
}
provider "aws" {
region = "us-east-1"
}
# VPC
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
enable_dns_hostnames = true
tags = { Name = "tf-lab-vpc" }
}
# Subnet pública
resource "aws_subnet" "public" {
vpc_id = aws_vpc.main.id
cidr_block = "10.0.1.0/24"
map_public_ip_on_launch = true
availability_zone = "us-east-1a"
tags = { Name = "tf-lab-public" }
}
# Internet Gateway
resource "aws_internet_gateway" "gw" {
vpc_id = aws_vpc.main.id
tags = { Name = "tf-lab-igw" }
}
# Route Table
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.gw.id
}
tags = { Name = "tf-lab-rt" }
}
resource "aws_route_table_association" "public" {
subnet_id = aws_subnet.public.id
route_table_id = aws_route_table.public.id
}
# Security Group
resource "aws_security_group" "web" {
name = "tf-lab-web-sg"
vpc_id = aws_vpc.main.id
ingress {
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = { Name = "tf-lab-sg" }
}
# EC2
resource "aws_instance" "web" {
ami = "ami-0c02fb55956c7d316"
instance_type = "t3.micro"
subnet_id = aws_subnet.public.id
vpc_security_group_ids = [aws_security_group.web.id]
user_data = <<-EOT
#!/bin/bash
yum install -y httpd
systemctl start httpd
echo "Terraform Lab - $(hostname)
" > /var/www/html/index.html
EOT
tags = { Name = "tf-lab-web" }
}
output "public_ip" {
value = aws_instance.web.public_ip
}
output "url" {
value = "http://${aws_instance.web.public_ip}"
}
EOFPasso 3 — Init, Plan, Apply
# Inicializar (baixa providers)
terraform init
# Ver o que vai criar (dry-run)
terraform plan
# Criar a infraestrutura
terraform apply -auto-approve✅ Validação:
# Ver outputs
terraform output
# Testar o site
curl http://$(terraform output -raw public_ip)
# Ver estado
terraform state listPasso 4 — Modificar (update in-place)
# Mudar instance type para t3.small
sed -i 's/t3.micro/t3.small/' main.tf
# Ver diff
terraform plan
# Vai mostrar: ~ update in-place (instance será parada e reiniciada)
terraform apply -auto-approvePasso 5 — Destroy (cleanup)
terraform destroy -auto-approve
# Remove TUDO que foi criadoterraform plan antes de apply. Em produção, use remote state (S3 + DynamoDB lock) para trabalho em equipe.terraform destroy é irreversível! Em produção, use lifecycle { prevent_destroy = true } em recursos críticos.💰O nível gratuito da AWS agora oferece US$ 200 em créditos
Fácil 5 minAWS • Free Tier • Créditos • FinOps
O nível gratuito da AWS agora oferece US$ 200 em créditos
e um plano gratuito de 6 meses para explorar a AWS sem nenhum custo

Hoje, a AWS anuncia melhorias em seu programa Free Tier, oferecendo a novos clientes até US$ 200 em créditos AWS para avaliar mais de 200 serviços. Este programa beneficia uma ampla gama de usuários, incluindo profissionais de nuvem, desenvolvedores de software, estudantes e empreendedores iniciantes, que desejam obter experiência prática com os serviços da AWS, desenvolver novas habilidades e criar provas de conceito. Com o novo AWS Free Tier, novos clientes podem explorar o amplo portfólio de serviços da AWS sem incorrer em custos, facilitando o início da utilização da AWS.
Como parte do programa Free Tier aprimorado, novos clientes recebem US$ 100 em créditos AWS ao se inscreverem e podem ganhar US$ 100 adicionais em créditos usando serviços como Amazon EC2 e Amazon Bedrock. Ele oferece aos clientes acesso a um número maior de serviços da AWS, ao mesmo tempo em que lhes dá controle sobre a transição para o uso pago. Além da capacidade de aplicar créditos a serviços pagos, os clientes continuam tendo acesso a mais de 30 serviços sempre gratuitos. Além disso, o novo Plano Gratuito é integrado ao conjunto de ferramentas de Gerenciamento Financeiro em Nuvem da AWS, facilitando o monitoramento e a previsão do uso futuro.
Os clientes podem começar a usar os novos recursos do programa Plano Gratuito da AWS selecionando o plano de conta gratuita durante a inscrição. O plano de conta gratuita expira 6 meses após a inscrição ou quando os créditos do Plano Gratuito se esgotarem, o que ocorrer primeiro. Quando estiverem prontos, os clientes podem facilmente atualizar para o plano pago com um único clique para obter acesso a mais serviços e continuar desenvolvendo na AWS.
Os novos recursos do Plano Gratuito da AWS estão disponíveis em todas as regiões da AWS, exceto nas regiões AWS GovCloud (EUA) e China. Para saber mais, visite o site do Plano Gratuito da AWS e a documentação do Plano Gratuito da AWS .
🔔Como Ser Notificado em Tempo Real Sobre Novos Recursos Provisionados na AWS
Médio 25 minEventBridge • SNS • CloudTrail • Compliance
Como Ser Notificado em Tempo Real Sobre Novos Recursos Provisionados na AWS

Hoje em dia, o mundo gira em torno de FinOps. E nem sempre os times de Engenharia ou FinOps conseguem acompanhar, em tempo real, tudo o que é provisionado ou deletado na AWS.
Pensando nisso, desenvolvi uma automação simples que permite monitorar, em tempo real, a criação e exclusão de recursos na AWS — com direito a notificações no Slack ou WhatsApp.
Com ela, é possível saber o que foi provisionado ou removido, por quem, e se a ação foi devidamente autorizada. Uma maneira prática de aumentar a rastreabilidade e evitar surpresas na conta no fim do mês.
🎯 Objetivo
Enviar notificações para o Slack ou Whatsapp sempre que recursos como EC2, RDS, Lambda ou S3 forem criados ou deletados na AWS, garantindo que **nenhuma notificação duplicada** seja enviada, usando DynamoDB como controle.
🔧 Serviços Utilizados
- AWS Lambda
- Amazon EventBridge
- Amazon DynamoDB
- Slack Webhook
📝 Pré-requisitos
- AWS CLI configurado (`aws configure`)
- Permissões para criar:
- Lambda
- EventBridge Rules
- DynamoDB
- URL de Webhook do Slack (Para o uso do audit-security-aws-slack.sh)
- Python 3.8 ou superior na Lambda
- Permissões IAM para a Lambda:
- dynamodb:GetItem
- dynamodb:PutItem
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Para facilitar a vida de todos, não vou seguir um passo a passo tradicional.
Em vez disso, desenvolvi um script que automatiza toda a criação dos recursos necessários.
Ele executa cada etapa automaticamente, solicitando apenas as informações essenciais para que tudo seja provisionado corretamente — de forma rápida, simples e segura.
#!/bin/bash
set -euo pipefail
echo "🔧 Setup Interativo - Notificações AWS Multi-Região para Slack via Lambda"
# Configurações interativas
read -rp "📍 Região AWS padrão para recursos (ex: us-east-2): " REGION
read -rp "🔑 Profile AWS CLI (ex: stream): " PROFILE
read -rp "🌐 URL do Webhook do Slack: " SLACK_WEBHOOK_URL
read -rp "📦 Nome da função Lambda (padrão: NotifySlackOnResourceCreation): " LAMBDA_NAME
LAMBDA_NAME=${LAMBDA_NAME:-NotifySlackOnResourceCreation}
read -rp "📚 Nome da Tabela DynamoDB (padrão: ProcessedEvents): " DDB_TABLE
DDB_TABLE=${DDB_TABLE:-ProcessedEvents}
# Configurações fixas para CloudTrail
CLOUDTRAIL_BUCKET_NAME="cloudtrail-global-center"
CLOUDTRAIL_BUCKET_REGION="us-east-1"
CLOUDTRAIL_NAME="MultiRegionTrail"
TMP_DIR=$(mktemp -d)
cleanup() {
rm -rf "$TMP_DIR"
rm -f function.zip
}
trap cleanup EXIT
echo "📡 Recuperando ID da conta AWS..."
ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text --region "$REGION" --profile "$PROFILE" 2>/dev/null)
echo "✅ Conta AWS: $ACCOUNT_ID"
# Passo 1: Configurar CloudTrail Multi-Região
echo "🔍 Configurando CloudTrail Multi-Região..."
if ! aws s3 ls "s3://$CLOUDTRAIL_BUCKET_NAME" --region "$CLOUDTRAIL_BUCKET_REGION" --profile "$PROFILE" &>/dev/null; then
echo "🪣 Criando bucket S3 centralizado..."
aws s3 mb "s3://$CLOUDTRAIL_BUCKET_NAME" --region "$CLOUDTRAIL_BUCKET_REGION" --profile "$PROFILE" &>/dev/null
fi
echo "🔑 Aplicando política multi-região..."
cat > "$TMP_DIR/s3-policy.json" <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AWSCloudTrailAclCheck",
"Effect": "Allow",
"Principal": {"Service": "cloudtrail.amazonaws.com"},
"Action": "s3:GetBucketAcl",
"Resource": "arn:aws:s3:::$CLOUDTRAIL_BUCKET_NAME"
},
{
"Sid": "AWSCloudTrailWriteMultiRegion",
"Effect": "Allow",
"Principal": {"Service": "cloudtrail.amazonaws.com"},
"Action": "s3:PutObject",
"Resource": [
"arn:aws:s3:::$CLOUDTRAIL_BUCKET_NAME/AWSLogs/$ACCOUNT_ID/*",
"arn:aws:s3:::$CLOUDTRAIL_BUCKET_NAME/AWSLogs/$ACCOUNT_ID/CloudTrail/*"
],
"Condition": {
"StringEquals": {
"s3:x-amz-acl": "bucket-owner-full-control",
"aws:SourceArn": "arn:aws:cloudtrail:*:$ACCOUNT_ID:trail/*"
}
}
}
]
}
EOF
aws s3api put-bucket-policy --bucket "$CLOUDTRAIL_BUCKET_NAME" \
--policy "file://$TMP_DIR/s3-policy.json" \
--region "$CLOUDTRAIL_BUCKET_REGION" --profile "$PROFILE" &>/dev/null
if ! aws cloudtrail describe-trails --trail-name-list "$CLOUDTRAIL_NAME" \
--region "$CLOUDTRAIL_BUCKET_REGION" --profile "$PROFILE" &>/dev/null; then
echo "🌍 Criando trail multi-região..."
aws cloudtrail create-trail --name "$CLOUDTRAIL_NAME" \
--s3-bucket-name "$CLOUDTRAIL_BUCKET_NAME" \
--is-multi-region-trail \
--region "$CLOUDTRAIL_BUCKET_REGION" \
--profile "$PROFILE" &>/dev/null
aws cloudtrail start-logging --name "$CLOUDTRAIL_NAME" \
--region "$CLOUDTRAIL_BUCKET_REGION" --profile "$PROFILE" &>/dev/null
else
echo "✅ CloudTrail já configurado."
fi
# Passo 2: Configurar DynamoDB
echo "🗃️ Criando tabela DynamoDB..."
if ! aws dynamodb describe-table --table-name "$DDB_TABLE" \
--region "$REGION" --profile "$PROFILE" &>/dev/null; then
aws dynamodb create-table --table-name "$DDB_TABLE" \
--attribute-definitions AttributeName=event_id,AttributeType=S \
--key-schema AttributeName=event_id,KeyType=HASH \
--billing-mode PAY_PER_REQUEST \
--region "$REGION" \
--profile "$PROFILE" &>/dev/null
aws dynamodb wait table-exists --table-name "$DDB_TABLE" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
else
echo "⚠️ Tabela já existe."
fi
echo "⏳ Configurando TTL..."
aws dynamodb update-time-to-live --table-name "$DDB_TABLE" \
--time-to-live-specification "Enabled=true,AttributeName=ttl" \
--region "$REGION" --profile "$PROFILE" &>/dev/null || true
# Passo 3: Configurar Lambda
echo "📦 Empacotando código Lambda..."
cp lambda_function.py "$TMP_DIR/lambda_function.py"
sed -i "s/AWS_REGION = \"us-east-1\"/AWS_REGION = \"$REGION\"/" "$TMP_DIR/lambda_function.py"
zip -qj function.zip "$TMP_DIR/lambda_function.py"
echo "🔐 Criando IAM Role..."
cat > "$TMP_DIR/trust-policy.json" <<EOF
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Principal": {"Service": "lambda.amazonaws.com"},
"Action": "sts:AssumeRole"
}]
}
EOF
ROLE_ARN=$(aws iam create-role --role-name "LambdaSlackNotifyRole" \
--assume-role-policy-document "file://$TMP_DIR/trust-policy.json" \
--query 'Role.Arn' --output text --region "$REGION" --profile "$PROFILE" 2>/dev/null || \
aws iam get-role --role-name "LambdaSlackNotifyRole" --query 'Role.Arn' --output text \
--region "$REGION" --profile "$PROFILE" 2>/dev/null)
cat > "$TMP_DIR/lambda-policy.json" <<EOF
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": ["dynamodb:GetItem", "dynamodb:PutItem"],
"Resource": "arn:aws:dynamodb:$REGION:$ACCOUNT_ID:table/$DDB_TABLE"
},{
"Effect": "Allow",
"Action": "logs:*",
"Resource": "*"
}]
}
EOF
aws iam put-role-policy --role-name "LambdaSlackNotifyRole" \
--policy-name "LambdaDynamoDBPermissions" \
--policy-document "file://$TMP_DIR/lambda-policy.json" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
echo "🚀 Criando função Lambda..."
aws lambda create-function --function-name "$LAMBDA_NAME" \
--runtime python3.13 --handler lambda_function.lambda_handler \
--zip-file fileb://function.zip --role "$ROLE_ARN" \
--timeout 03 --memory-size 128 \
--environment "Variables={SLACK_WEBHOOK_URL=$SLACK_WEBHOOK_URL,DDB_TABLE=$DDB_TABLE}" \
--region "$REGION" --profile "$PROFILE" &>/dev/null || echo "⚠️ Lambda já existe."
# Passo 4: Configurar EventBridge
echo "📅 Criando regra do EventBridge..."
cat > "$TMP_DIR/event-pattern.json" <<EOF
{
"source": ["aws.ec2", "aws.rds", "aws.lambda", "aws.s3"],
"detail-type": ["AWS API Call via CloudTrail"],
"detail": {
"eventName": [
"RunInstances", "TerminateInstances",
"CreateDBInstance", "DeleteDBInstance",
"CreateFunction20150331", "DeleteFunction20150331",
"CreateBucket", "DeleteBucket"
]
}
}
EOF
RULE_ARN=$(aws events put-rule --name "NotifyOnAWSResourceChange" \
--event-pattern "file://$TMP_DIR/event-pattern.json" \
--state ENABLED --region "$REGION" --profile "$PROFILE" \
--query 'RuleArn' --output text 2>/dev/null)
aws events put-targets --rule "NotifyOnAWSResourceChange" \
--targets "Id=NotifySlackLambda,Arn=arn:aws:lambda:$REGION:$ACCOUNT_ID:function:$LAMBDA_NAME" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
aws lambda add-permission --function-name "$LAMBDA_NAME" \
--statement-id "EventBridgeAccess" --action "lambda:InvokeFunction" \
--principal "events.amazonaws.com" --source-arn "$RULE_ARN" \
--region "$REGION" --profile "$PROFILE" &>/dev/null || true
# Passo 5: Cleanup opcional
read -rp "🧨 Deseja remover todos os recursos? (y/N): " DELETE_CONFIRM
if [[ "$DELETE_CONFIRM" =~ ^[Yy]$ ]]; then
echo "❌ Removendo recursos..."
aws events remove-targets --rule "NotifyOnAWSResourceChange" --ids "NotifySlackLambda" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
aws events delete-rule --name "NotifyOnAWSResourceChange" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
aws lambda delete-function --function-name "$LAMBDA_NAME" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
aws iam delete-role-policy --role-name "LambdaSlackNotifyRole" \
--policy-name "LambdaDynamoDBPermissions" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
aws iam delete-role --role-name "LambdaSlackNotifyRole" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
aws dynamodb delete-table --table-name "$DDB_TABLE" \
--region "$REGION" --profile "$PROFILE" &>/dev/null
aws cloudtrail stop-logging --name "$CLOUDTRAIL_NAME" \
--region "$CLOUDTRAIL_BUCKET_REGION" --profile "$PROFILE" &>/dev/null
aws cloudtrail delete-trail --name "$CLOUDTRAIL_NAME" \
--region "$CLOUDTRAIL_BUCKET_REGION" --profile "$PROFILE" &>/dev/null
echo "✅ Recursos removidos!"
fi
# Limpeza final
rm -f function.zip "$TRUST_POLICY"
echo "🎉 Configuração concluída com sucesso!"
Também será necessário incluir a função Lambda no diretório do seu script shell.
Ela será responsável por executar a lógica de notificação e deve estar presente para que o código seja compactado corretamente e enviado à AWS durante o provisionamento automático.
Ou seja, tudo estará no mesmo diretório, facilitando o empacotamento e a implantação do recurso.
Crie o arquivo chamado “lambda_function.py”
import json
import urllib3
import hashlib
import boto3
import time
import os
from botocore.exceptions import ClientError
AWS_REGION = "us-east-1" # Por padrão ao executar notification.sh ele vai alterar automaticamente
SLACK_WEBHOOK_URL = os.environ["SLACK_WEBHOOK_URL"] # Variável será obtida pelo notification.sh
DYNAMO_TABLE = os.environ.get("DDB_TABLE", "ProcessedEvents") # Tabela Default é ProcessedEvents
http = urllib3.PoolManager()
dynamodb = boto3.client("dynamodb", region_name=AWS_REGION)
ec2 = boto3.client("ec2", region_name=AWS_REGION)
EMOJIS = {
"EC2": ":rocket:",
"RDS": ":floppy_disk:",
"LAMBDA": ":pencil2:",
"S3": ":package:"
}
def generate_event_id(event):
event_name = event.get("detail", {}).get("eventName", "unknown")
user = event.get("detail", {}).get("userIdentity", {}).get("arn", "unknown")
time_str = event.get("time", "")
time_block = int(time.mktime(time.strptime(time_str, "%Y-%m-%dT%H:%M:%SZ"))) // 10
composite_key = f"{event_name}:{user}:{time_block}"
return hashlib.md5(composite_key.encode("utf-8")).hexdigest()
def is_duplicate(event_id):
try:
response = dynamodb.get_item(
TableName=DYNAMO_TABLE,
Key={"event_id": {"S": event_id}}
)
return "Item" in response
except ClientError as e:
print("Erro no DynamoDB:", e)
return False
def mark_processed(event_id):
ttl = int(time.time()) + 3600 # expira em 1h
try:
dynamodb.put_item(
TableName=DYNAMO_TABLE,
Item={
"event_id": {"S": event_id},
"ttl": {"N": str(ttl)}
}
)
except ClientError as e:
print("Erro ao salvar no DynamoDB:", e)
def build_slack_message(title, fields, console_link=None, emoji=":cloud:"):
message = [
{"type": "section", "text": {"type": "mrkdwn", "text": f"{emoji} *{title}*"}},
{"type": "section", "fields": [{"type": "mrkdwn", "text": f"*{k}:*\n{v}"} for k, v in fields.items()]}
]
if console_link:
message.append({
"type": "actions",
"elements": [{
"type": "button",
"text": {"type": "plain_text", "text": "🔗 Ver no Console AWS"},
"url": console_link
}]
})
return message
def default_fields(user_identity):
return {
"Região": AWS_REGION,
"Usuário": f"`{user_identity}`"
}
def lambda_handler(event, context):
print("Evento recebido:", json.dumps(event))
event_id = generate_event_id(event)
if is_duplicate(event_id):
print("Evento duplicado, ignorando:", event_id)
return {'statusCode': 200, 'body': 'Evento duplicado ignorado'}
mark_processed(event_id)
detail = event.get("detail", {})
event_name = detail.get("eventName", "")
user_identity = detail.get("userIdentity", {}).get("arn", "Desconhecido")
source_service = event.get("source", "aws.unknown").split(".")[-1].upper()
emoji = EMOJIS.get(source_service, ":cloud:")
blocks = []
if event_name == "RunInstances":
params = detail.get("requestParameters", {})
instance_type = params.get("instanceType", "N/A")
ami_id = params.get("imageId", "N/A")
# EBS
block_items = params.get("blockDeviceMapping", {}).get("items", [])
ebs_size = block_items[0].get("ebs", {}).get("volumeSize", "N/A") if block_items else "N/A"
# Nome (via tags)
tags = params.get("tagSpecificationSet", {}).get("items", [])
name_tag = next(
(t["value"] for tag_set in tags for t in tag_set.get("tags", []) if t["key"] == "Name"),
"N/A"
)
# SGs e IP público
ni_items = params.get("networkInterfaceSet", {}).get("items", [])
has_public_ip = ni_items[0].get("associatePublicIpAddress", False) if ni_items else False
sg_items = ni_items[0].get("groupSet", {}).get("items", []) if ni_items else []
sg_ids = [sg.get("groupId", "N/A") for sg in sg_items]
ip_status = "✅ Sim" if has_public_ip else "❌ Não"
blocks = build_slack_message(
title="Instância EC2 Criada!",
emoji=emoji,
fields={
**default_fields(user_identity),
"Tipo": instance_type,
"Nome": name_tag,
"AMI": ami_id,
"Volume EBS": f"{ebs_size} GB",
"IP Público": ip_status,
"Security Groups": ", ".join(sg_ids)
},
console_link=f"https://{AWS_REGION}.console.aws.amazon.com/ec2/v2/home?region={AWS_REGION}#Instances:instanceId={params.get('instanceId', 'N/A')}"
)
elif event_name == "TerminateInstances":
instance_ids = [i["instanceId"] for i in detail.get("requestParameters", {}).get("instancesSet", {}).get("items", [])]
name_tag = "N/A"
launch_time = "Desconhecido"
try:
reservations = ec2.describe_instances(InstanceIds=instance_ids).get("Reservations", [])
if reservations and reservations[0]["Instances"]:
instance = reservations[0]["Instances"][0]
launch_time = instance.get("LaunchTime", "").strftime("%Y-%m-%d %H:%M:%S")
tags = instance.get("Tags", [])
name_tag = next((tag["Value"] for tag in tags if tag["Key"] == "Name"), "N/A")
except ClientError as e:
print("Erro ao buscar detalhes da instância:", e)
termination_time = event.get("time", "Desconhecido")
blocks = build_slack_message(
title="Instância EC2 Terminada!",
emoji=":x:",
fields={
**default_fields(user_identity),
"Instâncias": ", ".join(instance_ids),
"Nome": name_tag,
"Criado em": launch_time,
"Deletado em": termination_time
}
)
elif event_name == "CreateDBInstance":
params = detail.get("requestParameters", {})
db_id = params.get("dBInstanceIdentifier", "N/A")
engine = params.get("engine", "N/A")
class_type = params.get("dBInstanceClass", "N/A")
blocks = build_slack_message(
title="Instância RDS Criada!",
emoji=emoji,
fields={
**default_fields(user_identity),
"DB ID": db_id,
"Engine": engine,
"Classe": class_type
},
console_link=f"https://{AWS_REGION}.console.aws.amazon.com/rds/home?region={AWS_REGION}#database:id={db_id};is-cluster=false"
)
elif event_name == "DeleteDBInstance":
db_id = detail.get("requestParameters", {}).get("dBInstanceIdentifier", "N/A")
blocks = build_slack_message(
title="Instância RDS Deletada!",
emoji=":x:",
fields={
**default_fields(user_identity),
"DB ID": db_id
}
)
elif event_name == "CreateFunction20150331":
fn_name = detail.get("requestParameters", {}).get("functionName", "N/A")
runtime = detail.get("requestParameters", {}).get("runtime", "N/A")
blocks = build_slack_message(
title="Função Lambda Criada!",
emoji=emoji,
fields={
**default_fields(user_identity),
"Nome": fn_name,
"Runtime": runtime
},
console_link=f"https://{AWS_REGION}.console.aws.amazon.com/lambda/home?region={AWS_REGION}#/functions/{fn_name}"
)
elif event_name == "DeleteFunction20150331":
fn_name = detail.get("requestParameters", {}).get("functionName", "N/A")
blocks = build_slack_message(
title="Função Lambda Deletada!",
emoji=":x:",
fields={
**default_fields(user_identity),
"Função": fn_name
}
)
elif event_name == "CreateBucket":
bucket = detail.get("requestParameters", {}).get("bucketName", "N/A")
blocks = build_slack_message(
title="Bucket S3 Criado!",
emoji=emoji,
fields={
**default_fields(user_identity),
"Bucket": bucket
},
console_link=f"https://s3.console.aws.amazon.com/s3/buckets/{bucket}?region={AWS_REGION}"
)
elif event_name == "DeleteBucket":
bucket = detail.get("requestParameters", {}).get("bucketName", "N/A")
blocks = build_slack_message(
title="Bucket S3 Deletado!",
emoji=":x:",
fields={
**default_fields(user_identity),
"Bucket": bucket
}
)
else:
blocks = build_slack_message(
title=f"Evento não categorizado: {event_name}",
fields={"Usuário": f"`{user_identity}`"},
emoji=":warning:"
)
# Envia mensagem para o Slack
response = http.request(
'POST',
SLACK_WEBHOOK_URL,
body=json.dumps({"blocks": blocks}),
headers={'Content-Type': 'application/json'}
)
return {
'statusCode': response.status,
'body': response.data.decode('utf-8')
}
Importante: mantenha os créditos à minha autoria.
Se este material te ajudou como engenheiro ou profissional de FinOps, ótimo — é exatamente esse o objetivo.
Mas não tome para si o crédito por algo que você apenas utilizou. Reconhecer o trabalho dos outros é uma atitude de respeito e profissionalismo.
# Autor: Diego Norman
📡Configuração do AWS IoT Core com Domínio Personalizado e Comunicação de Dispositivos
Avançado 45 minIoT Core • Route53 • MQTT • Certificados
Configuração do AWS IoT Core com Domínio Personalizado e Comunicação de Dispositivos
A personalização de domínio no IoT Core facilita o gerenciamento dos dispositivos IoT e a segurança nas conexões. Para criar e configurar o domínio personalizado, siga estas etapas:
1. Configuração do dominio:
Agora, vamos acessar a funcionalidade “IoT Core” em “Configurações de Domínio”.
Depois, clique em “Criar configuração de domínio”.
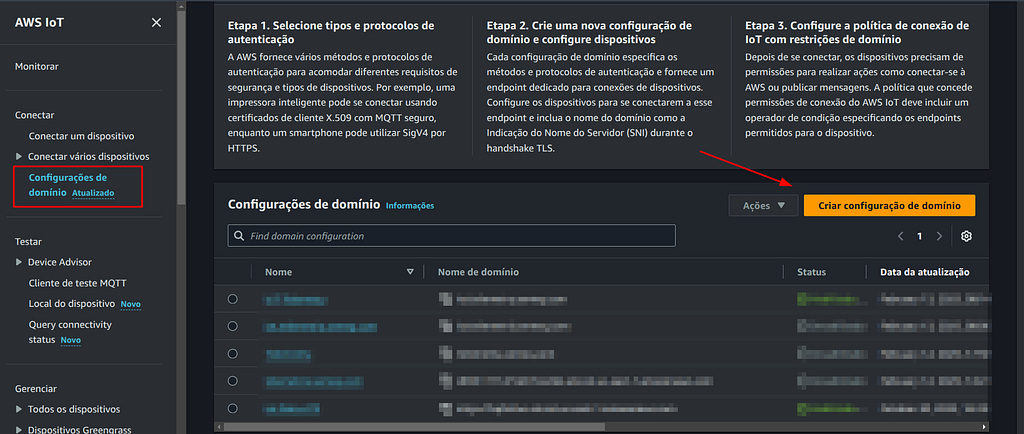
Nome: Escolha um nome à sua preferência ou use o seu domínio.
Exemplo: iot.seudominio.com
Política de segurança: Pode deixar o padrão (default).
Tipo de domínio: Selecione “Domínio gerenciado pelo cliente”.
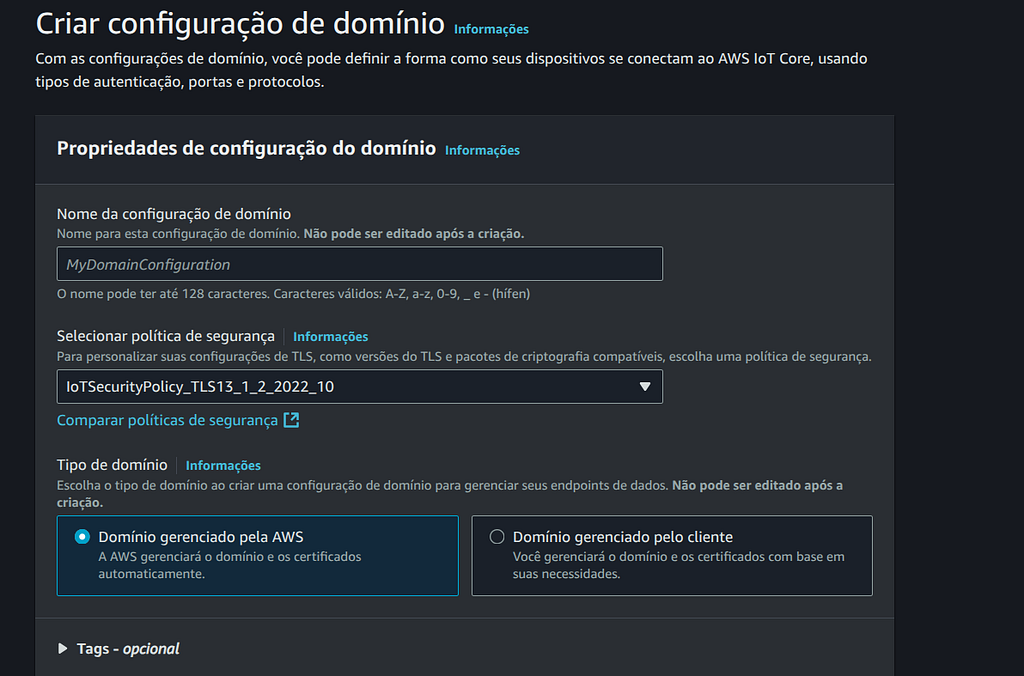
Nome de domínio: Adicione o seu domínio.
Exemplo: iot.seudominio.com
Certificado do Servidor: Você precisa criar um certificado no ACM para o seu domínio. Clique em “Criar certificado com ACM”. Após isso, selecione o certificado criado.
Certificado de validação: Deixe em branco.
Obs: Não estou abordando aqui como criar o domínio e registrá-lo no Route 53, pois entendo que você já deve ter esse conhecimento.

Configuração de Autenticação:
Escolha a opção que melhor se encaixa nas necessidades do seu projeto. Eu, por exemplo, vou utilizar o Padrão ALPN.

Autorizador Personalizado:
Escolha conforme as necessidades do seu projeto. No meu caso, vou utilizar a opção “Nenhum Autorizador Personalizado”.
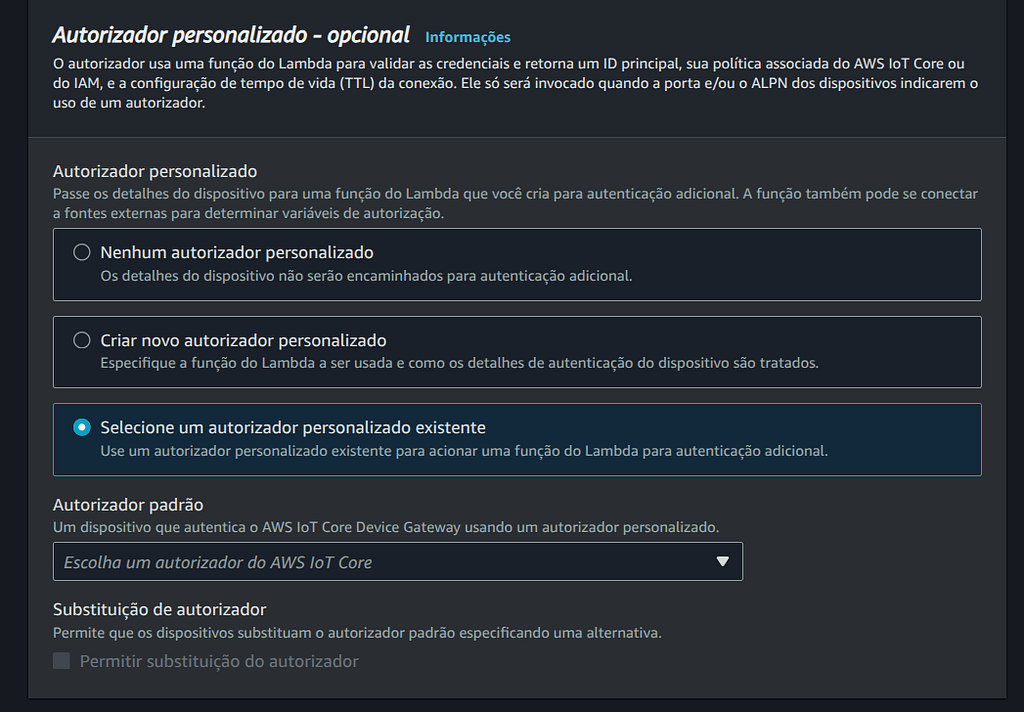
Resumo da Configuração de Autenticação:
Agora, vamos habilitar a configuração.
Agora “Criar configuração de domínio.

Agora, vamos em Segurança, depois em Políticas e, em seguida, clique em Criar política.
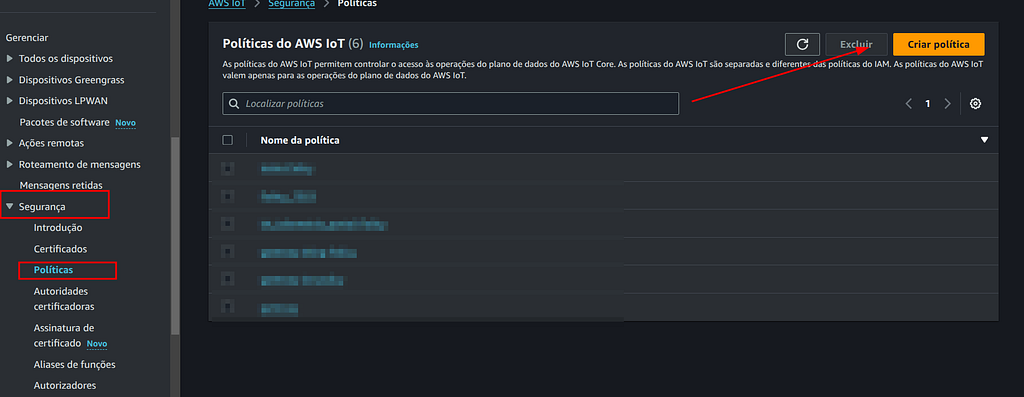
Nome da Política: Adicione o nome que preferir. Eu geralmente deixo algo parecido com o domínio que foi criado.
Documento da Política: Aqui, vamos deixar permissões para tudo, mas você pode granularizar com o ARN (Amazon Resource Name) no recurso da política, se necessário.
Efeito da Política: Geralmente, definimos o efeito que a política terá, como “Allow” (Permitir) ou “Deny” (Negar).
Ação da Política: Defina qual ação a política vai permitir ou negar.
Recursos da Política: Pode definir os recursos afetados pela política. O padrão é “*” para tudo, mas você pode granularizar utilizando o ARN, como mencionamos antes.
Geralmente, eu crio 3 linhas de instrução para a política.
Você também pode criar a política usando o formato JSON. Abaixo, vou deixar o exemplo de como minha política ficará em JSON:
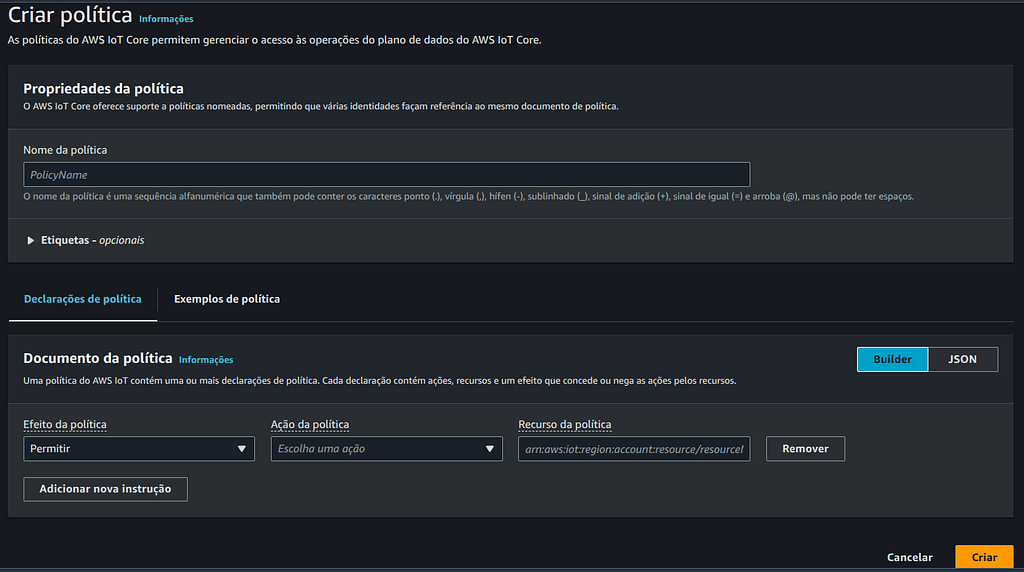
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iot:Publish",
"iot:Receive",
"iot:PublishRetain"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "iot:Subscribe",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": "iot:Connect",
"Resource": "*"
}
]
}
Esse é um exemplo simples de política, onde “Effect” é “Allow”, permitindo todas as ações (“Action”: “*”) em todos os recursos (“Resource”: “*”). Você pode ajustar o ARN ou as permissões conforme a necessidade do seu projeto.
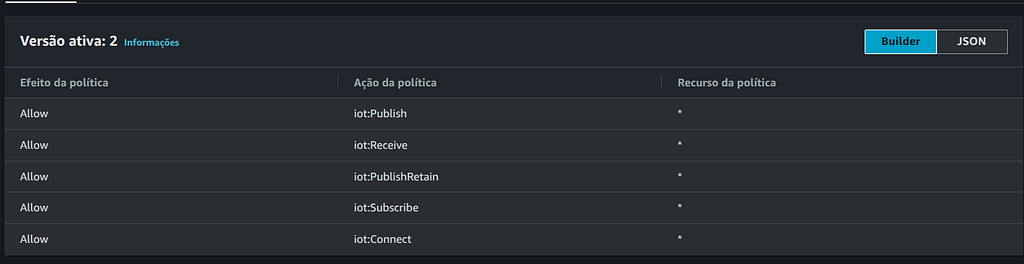
Agora, vamos criar um certificado para a política que acabamos de criar. Siga os passos abaixo:
Vá até Segurança e depois em Certificados.
Clique em Adicionar certificado.
Após isso, clique em Criar certificado (igual à imagem abaixo).
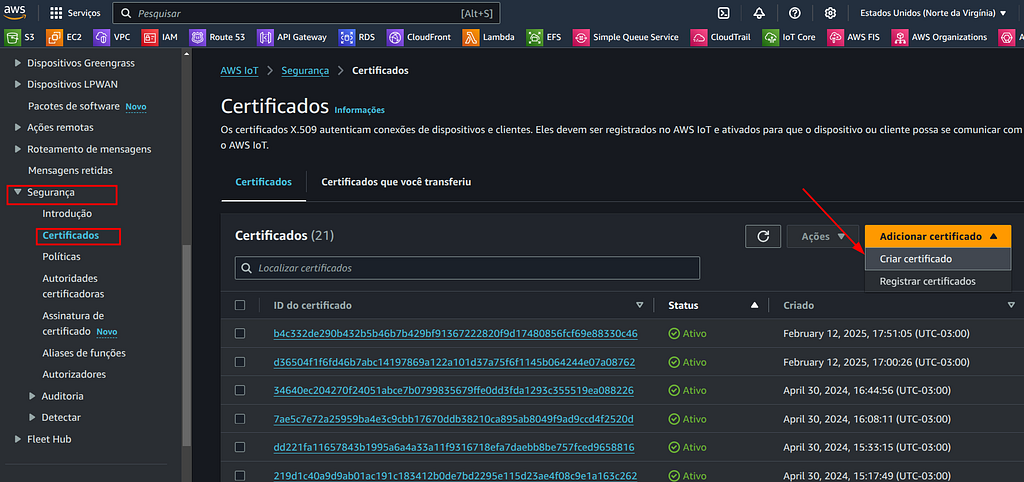
Na Seleção de ramificação de Certificado, deixe a opção recomendada, conforme mostrado na imagem.
Em Seleção de status de certificado, marque a opção como Ativo.
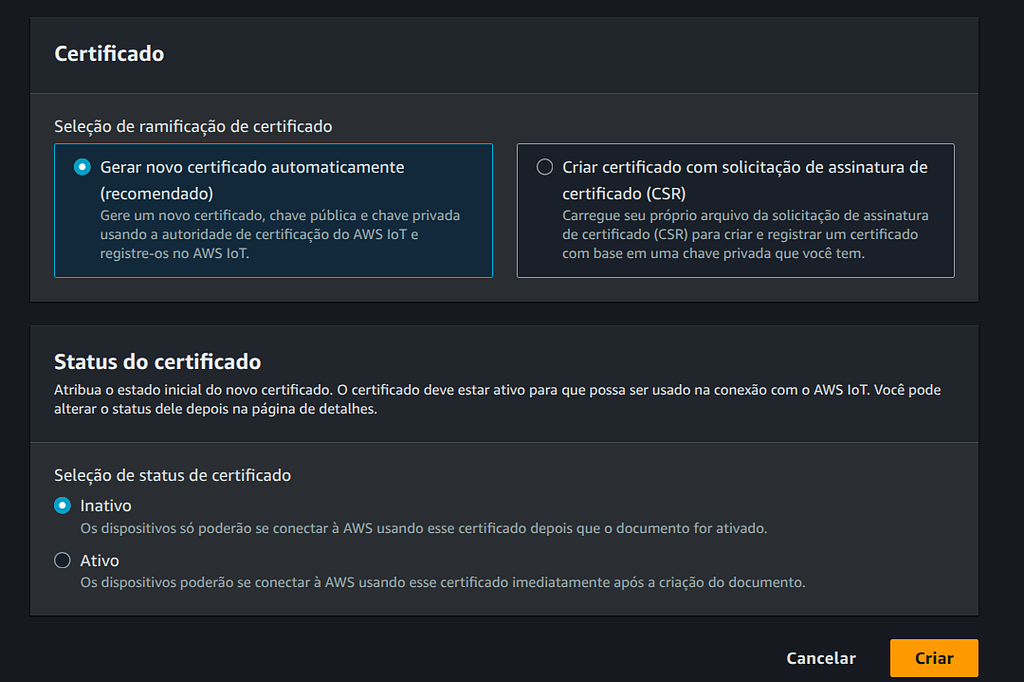
Lembrando que, após criar o certificado, vai aparecer uma aba para você baixar os certificados.
Você vai precisar baixar o Certificado do dispositivo. Em seguida, baixe o Arquivo de chave privada e o Certificado de CA Raiz. Porém, você pode baixar apenas o primeiro, o Certificado do dispositivo.
Eu geralmente renomeio os arquivos da seguinte forma:
- O Certificado do dispositivo eu renomeio como iot_dominio.pem, removendo a extensão .cert que vem nela.
- O Arquivo de chave privada eu renomeio, mas deixo o final como .key.
- O Certificado de CA Raiz eu renomeio para root-CA.crt.

Agora, vamos voltar para Certificados. O certificado criado aparecerá como uma hash, igual à imagem abaixo.
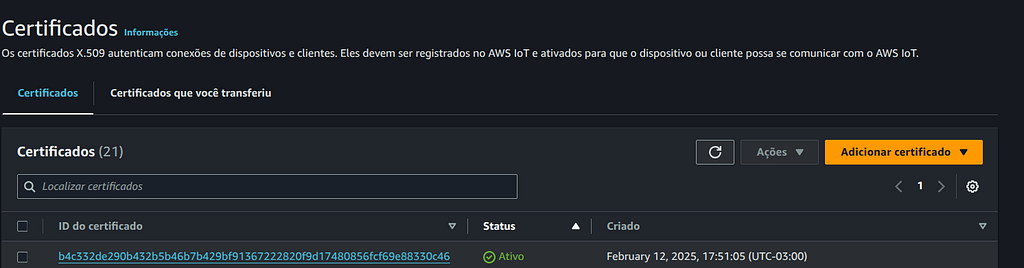
Agora, clique nessa hash e a configuração do certificado vai abrir.
Vá até Política e clique em Anexar políticas. Isso abrirá uma aba flutuante onde você vai selecionar a política que criamos anteriormente.
Depois, clique em Things (ou Coisas) e faça a mesma coisa: Anexar política.
Obs: Em Coisas, pode ser que o item ainda não exista. Nesse caso, você poderá criar um novo item. Vá até o menu Gerenciar, depois Coisas, e clique em Criar item.
Em seguida, clique em Criar um único item e depois em Próximo. Coloque o nome do item — geralmente, eu sigo o padrão iot.meudominio. Marque a opção Nenhum shadow para o dispositivo.

Agora, vamos voltar para o menu Configurações de domínio. Se você perceber, vai encontrar uma URL chamada iot:Data-ATS. A URL geralmente será algo como:
a3grx1fc2329vfue-ats.iot.us-east-1.amazonaws.com
Você vai adicionar essa URL como um CNAME no seu domínio lá no Route 53. Ou seja, o seu subdomínio iot.seudominio precisa apontar para:
a3grx1fc2329vfue-ats.iot.us-east-1.amazonaws.com
Agora, estamos quase no fim, e você deve estar se perguntando: “Está tudo bem? E agora, como eu consigo testar isso?”
Você pode ir no menu Conectar, depois em Conectar um dispositivo. Ele vai pedir que você faça um ping para a URL:
a3grx1fc2329vfue-ats.iot.us-east-1.amazonaws.com. Você fará o teste e deverá obter uma resposta.
Aproveite também para fazer o teste no domínio personalizado que você criou, ou seja, o iot.seudominio.
Agora, clique em Próximo. Vai aparecer uma nova tela. Nela, vá em “Escolha uma coisa existente” e selecione a coisa que você criou.
Agora, basta seguir o passo a passo que será instruído. Você poderá testar usando alguns SDKs, como Node.js, Python ou Java. Seguindo o tutorial, você conseguirá realizar o teste por completo.
Conclusão
Com esse passo a passo, você configurou com sucesso o AWS IoT Core com um domínio personalizado, configurou dispositivos, garantiu comunicação segura via MQTT e integrou seu sistema com outros serviços da AWS. Além disso, você implementou uma estrutura robusta de monitoramento e segurança, garantindo que seus dispositivos IoT operem de forma eficaz e segura.
Deixo claro que é possível deixar tudo extremamente seguro e robusto, utilizando ferramentas como o Cognito e outras soluções. Aqui, fornecemos apenas uma base para você ter algo funcional com o domínio da sua empresa ou projeto. A partir daqui, você pode evoluir e adicionar outras funcionalidades conforme a necessidade.